안녕하세요! 오늘은 국산 대규모 언어 모델 Solar 10.7B의 깊이(Depth) 업스케일링 기술에 대한 논문을 살펴보겠습니다. "깊이 업스케일링"은 대규모 언어 모델을 확장하기 위한 기술로, 주로 모델의 깊이(Depth)를 증가시키는 방법을 나타냅니다. 언어 모델의 깊이는 모델이 가지는 층(Layers)의 수를 의미하며, 이를 늘리는 것은 모델의 표현력과 성능을 향상시킬 수 있습니다. 이 블로그를 통해서 Solar 10.7B에 적용된 DUS(Depth Up-Scaling) 기술의 개요, 원리, 특성, 성능평가에 대해 확인하실 수 있습니다. 그럼, 출발하실까요?

논문 개요 및 목적
- 논문 제목: "SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling"
- 논문 저자: Upstage AI
- 논문게재 사이트: https://arxiv.org/abs/2312.15166
- 논문게재일: 2023년 12월
본 논문은 SOLAR 10.7B 대규모 언어 모델을 효과적으로 확장하는 간단하면서도 효과적인 "깊이 업스케일링(DUS, Depth Up-Scaling)" 기술을 소개합니다. 이 기술은 기존의 다른 확장 기술과 차별화되어 특정 훈련이나 추론 프레임워크 없이도 최대 효율성을 달성할 수 있습니다.


"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
논문의 연구내용 및 결과
SOLAR 10.7B에서 제시한 " 깊이 업스케일링, DUS(Depth Up-Scaling)" 기술은 기본 LLMs를 통해 깊이를 효과적으로 확장하는 간단하면서도 효과적인 방법입니다. 본 기술은 특별한 훈련이나 추론 프레임워크 없이도 구현 가능하며, Mixture of Experts(MoE)와 같은 다른 업스케일링 기술과의 비교에서 뛰어난 효율성을 보입니다. 접은 글 더보기를 클릭하시면 레이어의 개념을 확인해 보실 수 있습니다.
"레이어"라는 용어는 트랜스포머와 같은 딥러닝 모델의 소프트웨어적인 구성 요소를 나타내는 개념입니다. 이것은 실제로 물리적인 층이나 구조를 의미하지 않습니다. 딥러닝에서 레이어는 모델의 아키텍처에서 일종의 계층이라고 생각할 수 있습니다. 각 레이어는 데이터를 처리하고 특정 유형의 연산을 수행하는 단위로 구성되어 있습니다.
대규모 언어 모델에서 "레이어"는 주로 트랜스포머(Transformer) 아키텍처에서 사용되는 용어입니다. 트랜스포머는 주로 자연어 처리(NLP) 작업을 수행하는 데에 사용되는 딥러닝 아키텍처 중 하나로, 여러 개의 쌓인 레이어로 구성됩니다. 레이어는 모델의 기본 구성 요소로, 각 레이어는 일련의 연산을 수행하고 데이터를 변환합니다.
트랜스포머의 각 레이어는 세 가지 주요 부분으로 구성됩니다:
1. 자기 어텐션 메커니즘(Self-Attention Mechanism): 이 부분에서 입력 시퀀스의 각 위치에 대한 가중치를 계산하여 해당 위치와 다른 모든 위치 간의 상호 작용을 나타냅니다. 이를 통해 모델은 문맥을 파악하고 문장 내의 단어 간의 관계를 이해할 수 있습니다.
2. 피드포워드 신경망(Feedforward Neural Network): 어텐션 메커니즘의 출력을 기반으로 한 전방향 신경망이 뒤따라옵니다. 이 부분은 비선형성을 도입하고 더 복잡한 패턴을 학습할 수 있도록 도와줍니다.
3. 정규화 및 잔차 연결(Normalization and Residual Connection): 각 레이어의 출력에는 정규화(normalization)가 적용되며, 이후 잔차 연결(residual connection)이 수행됩니다. 잔차 연결은 네트워크가 더 깊어질 때 발생할 수 있는 그레이디언트 소실(일종의 정보손실) 문제에 대한 해결책으로, 각 레이어의 입력과 출력 간의 차이를 학습하도록 하는 구조를 갖추고 있습니다.
대규모 언어 모델에서는 이러한 레이어가 여러 층으로 쌓여 전체 모델이 형성됩니다. 레이어의 수가 많을수록 모델은 더 복잡한 문법 및 의미 구조를 학습할 수 있게 되며, 그 결과로 더 높은 수준의 언어 이해 및 생성 능력을 갖출 수 있습니다.
깊이 업스케일링의 핵심 원리는 다음 설명내용과 같이 LLM의 깊이를 확장하는 것입니다. 요약해서 말하면, 대규모 언어 모델의 성능 향상을 위해 초기 모델을 활용하고, 추가 데이터셋을 훈련한 후, 모델의 층을 확장함으로써 깊이를 증가시켜 모델의 언어 이해 능력을 향상시킵니다.
LLM의 깊이 업스케일링
대규모 언어 모델의 성능 향상을 위한 깊이 업스케일링은 다음과 같이 이루어 집니다.
- 1. 초기 모델 훈련: 작은 규모의 초기 모델을 훈련합니다. 이 모델은 적은 수의 층(layers)으로 구성되어 있으며, 기본적인 언어 이해와 생성 능력을 갖추고 있습니다.
- 2. 추가 데이터 수집: 다양한 소스에서 대규모의 데이터를 수집합니다. 이 데이터는 다양한 언어적 맥락과 특성을 포함하며, 초기 모델이 다루기 어려웠던 복잡한 패턴을 학습하는 데 사용됩니다.
- 3. 모델 재훈련: 초기 모델을 추가 데이터로 다시 훈련시킵니다. 이 단계에서는 초기 모델의 성능을 향상시키기 위해 새로운 데이터의 정보를 활용합니다.
- 4. 깊이 업스케일링: 훈련된 초기 모델의 층을 확장하여 깊이를 증가시킵니다. 이 과정에서 새로운 데이터의 학습 내용이 추가되며, 모델의 언어 이해 능력이 향상됩니다.
- 5. Fine-tuning 및 최적화: 필요한 경우, 추가적인 fine-tuning 및 최적화를 수행하여 최종 모델을 얻습니다.
이러한 과정을 통해 초기에는 상대적으로 작은 모델에서 시작하여 대규모 언어 모델을 얻게 되며, 증가된 깊이는 모델의 언어 처리 능력을 획기적으로 향상시킵니다.
SOLAR 깊이 업스케일링(DUS) 원리
- 기본 개념: DUS는 기존 LLM을 단순히 레이어를 한 번 더 반복하여 업스케일링하는 방법에서 시작합니다. 즉, 32개의 레이어에서 64개의 레이어로 확장합니다. 이것은 모델이 더 많은 계층을 통해 데이터를 처리하고 학습할 수 있게 하여, 더 복잡한 특징과 패턴을 인식하도록 하는 방법 중 하나입니다
- 장점: 32번째와 33번째 레이어를 제외하고는 모든 레이어가 기본 LLM에서 직접 가져와져서 '레이어 간 거리' 또는 기본 모델의 레이어 간 차이가 1보다 크지 않습니다. 성능 향상을 위해 초기에는 경계 부분 레이어의 불일치를 줄이는 데 중점을 둘 수 있으며, 이는 업스케일링된 모델의 성능을 신속하게 향상시킬 수 있습니다.
- 단점: 그러나 이러한 간단한 방법의 경우, 경계 부분에서 레이어 간 거리가 최대로 커져서 사전 훈련된 가중치의 효과적인 활용을 방해할 수 있습니다. 레이어 간 거리가 최대로 커지면 새로운 레이어가 이전 레이어와의 관계를 학습하기 어려워지며, 이로 인해 사전 훈련된 가중치의 효과적인 활용이 어려워집니다
- 깊이 업스케일 메서드: 이러한 단점을 극복하기 위해, 중간 레이어를 제거하고 기본 모델의 마지막 8개 레이어와 중복 모델의 처음 8개 레이어를 제거합니다. 각 모델은 24개의 레이어만 남게 되고, 이를 연결하여 48개 레이어와 10.7 억 개의 매개변수를 가진 깊이 업스케일링된 모델을 형성합니다. 이 결정은 성능 대 크기의 최적화를 목표로 하며, 중간 레이어를 제거함으로써 경계 부분의 레이어 간 거리를 줄입니다.
논문에서는 32개의 층을 가진 Llama2 아키텍처를 기본 모델로 사용하며, 이를 통해 깊이 업스케일링을 실시합니다. 추가로, 처음 24개의 층은 미리 훈련된 가중치를 사용하고 있습니다. 깊이 업스케일링을 통해 32개의 초기 층에서 마지막 8개의 레이어를 제거하고, 이를 복제한 모델에서 처음 8개의 레이어를 제거하여 최종적으로 48개의 층을 갖는 모델을 얻게 됩니다. 이러한 접근은 초기에는 적은 수의 층으로 모델을 학습시키면서도 깊이를 늘려 높은 성능의 언어 모델을 얻을 수 있도록 합니다.
SOLAR 깊이 업스케일링(DUS) 특성
깊이 업스케일링의 핵심적인 특성은 "중간레이어의 제거"이며, 세부적인 특성은 다음과 같습니다.
- 성능 대비 모델 크기의 최적화: 중간 레이어를 제거함으로써 모델의 깊이를 증가시킬 때 성능 대비 모델 크기를 효과적으로 제어할 수 있습니다. 논문에서는 성능 향상을 위해 중간 레이어를 희생하면서도, 모델의 깊이를 증가시킴으로써 성능을 일정 수준 유지하려는 목표를 가지고 있습니다.
- 레이어 간 거리 감소: 중간 레이어를 제거하면서 레이어 간의 거리를 감소시킴으로써 모델이 더 잘 최적화되고 사전 훈련된 가중치를 효과적으로 활용할 수 있도록 합니다. 거리가 감소하면, 즉, 새로운 레이어가 원본 레이어에 더 가깝게 위치하면서 더 쉽게 최적화될 수 있습니다.
- 모델 복잡성 제어: 중간 레이어를 제거함으로써 모델의 복잡성을 줄이고 효율적으로 메모리 및 계산 리소스를 사용할 수 있습니다. 특히, 중간 레이어를 제거하면 추가되는 레이어의 수가 줄어들어 모델이 더 간단해지는 효과가 있습니다.
- 모델의 단순화: MoE(Mixture of Experts) 접근과 달리 깊이 DUS는 추가적인 모듈이나 게이팅 네트워크, 전문가 선택 프로세스를 필요로 하지 않습니다. DUS 모델은 최적의 훈련 효율을 위한 별도의 훈련 프레임워크나 빠른 추론을 위한 특수한 CUDA 커널이 필요하지 않습니다. DUS로 업스케일링된 LLM은 기존의 훈련 및 추론 프레임워크에 신속하게 통합될 수 있으며 높은 효율을 유지합니다.
DUS는 간단하게 기존 모델의 일부 레이어를 잘라내어 복제하고, 이를 다시 결합하여 새로운 깊이의 모델을 생성하는 방식입니다. 이때, 중간 레이어를 일부 제거함으로써 모델의 성능과 크기 간의 균형을 조절합니다. 이로써 DUS는 MoE와 같은 복잡한 구조나 네트워크를 도입하지 않으면서도 모델 깊이를 효과적으로 확장할 수 있는 방법을 제시합니다.
| 특성 | Depth Up-Scaling (DUS) | 기존 깊이 업스케일링 방식 |
| 복잡성 | 간단하고 직관적 | 추가 모듈 및 복잡한 구조 |
| 모듈 요구사항 | 전문가 선택 또는 게이팅 네트워크 불필요 | 전문가 선택, 게이팅 네트워크 필요 |
| 훈련 및 추론 효율성 | 통합이 용이하고 빠른 성능 복구 | 특화된 훈련 및 추론 프레임워크 요구 |
| 모델 크기 대 성능 | 효율적인 크기 관리와 성능 유지 | 성능 향상을 위한 크기 증가 필요 |
| 경계 부분에서의 가중치 활용 | 효과적인 가중치 활용 및 레이어 간 거리 최소화 | 레이어 간 거리 최대화 및 가중치 효과 감소 |
| 모델 통합의 용이성 | 기존 훈련 및 추론 프레임워크와의 원활한 통합 | 특화된 프레임워크에 의존 |
SOLAR 성능평가 및 조정 훈련
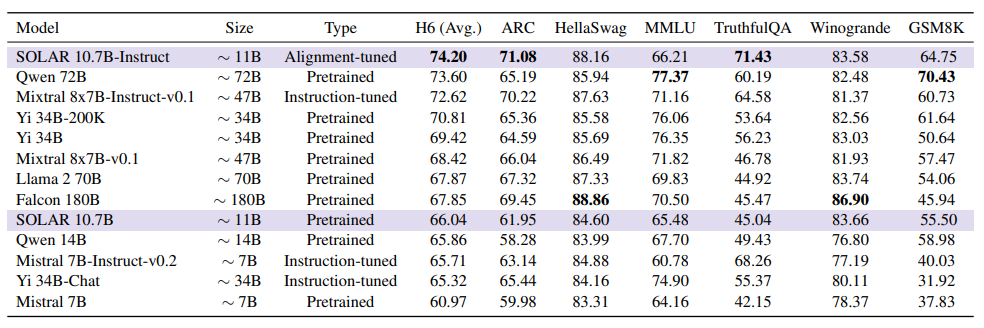
위 표를 살펴보면 SOLAR 10.7B 및 이의 fine-tuned 버전은 기존에 비해 탁월한 성능을 보입니다. Qwen 14B 및 Mistral 7B와 같은 유사한 규모의 사전 훈련된 모델을 능가하며, SOLAR 10.7B-Instruct는 특히 H6에서 우수한 성과를 기록합니다. 이는 깊이 업스케일링이 기본 LLMs를 확장하면서도 최첨단 성능을 달성할 수 있는 효과적인 방법임을 시사합니다. H6는 HuggingFace Open LLM Leaderboard에서 정의된 여섯 가지 평가 방법(ARC, HellaSWAG, MMLU, TruthfulQA, Winogrande, GSM8 K)의 평균값을 나타냅니다.
SOLAR 10.7B 모델의 훈련은 지시어 조정(Instruction Tuning)과 정렬 조정(Alignment Tuning) 두 가지 주요 단계로 이루어졌습니다.
- 지시어 조정: 모델이 특정 작업이나 지식 영역에 특화되도록 다양한 훈련 데이터셋을 사용하여 모델을 훈련시키는 과정. Alpaca-GPT4, OpenOrca, Synth. MathInstruct 데이터셋을 활용하여 여러 모델을 실험. OpenOrca를 사용한 모델은 GSM8K 작업에서 높은 성능을 보이지만, 다른 작업에서는 저조한 결과를 나타냄. Synth. Math-Instruct 데이터셋을 추가하면 모델의 성능 향상이 있음을 확인. 서로 다른 강점을 가진 모델을 병합하여 성능을 향상시키는 실험 진행.
- 정렬 조정: 모델의 편향을 보완하고 다양한 정렬 데이터셋을 사용하여 모델을 훈련시키는 과정. Ultrafeedback Clean, Synth. Math-Alignment 데이터셋을 활용하여 모델을 실험. Synth. Math-Alignment 데이터셋 추가는 H6 성능 향상에 도움이 되었으나 GSM8K에서는 성능 감소가 있음. 서로 다른 모델을 병합하는 실험 진행.
최종적으로는 Instruction Tuning과 Alignment Tuning을 조합하여 튜닝된 SOLAR 10.7B 모델이 얻어졌으며, 데이터셋 선택과 모델 병합 등 다양한 전략을 사용하여 모델의 성능을 향상시킬 수 있음을 확인하였습니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
마치며
오늘은 국산 대규모 언어 모델 SOLAR 10.7B에 적용된 DUS(Depth Up-Scaling) 기술의 기본 개념, 원리, 특성, 성능평가 등을 통해 이 기술이 어떻게 대규모 언어 모델의 성능을 향상시키는 데 기여하는지 알아보았습니다. 언어 모델의 깊이 업스케일링은 모델의 깊이를 증가시켜 성능을 향상시키는 중요한 기술 중 하나입니다. SOLAR 10.7B의 DUS(Depth Up-Scaling) 기술은 기존 방법과는 차별화된 간단하면서도 효과적인 방법을 제시하고 있습니다.
이러한 연구는 자연어 처리 분야에서의 지속적인 발전과 연구 동기부여를 제공하고 있습니다. SOLAR 10.7B의 Apache 2.0 오픈 소스 소프트웨어 라이선스는 다양한 연구자들과 협력하여 더 나은 언어 모델의 개발을 촉진할 것으로 기대됩니다. 우리나라 미래의 언어 모델 발전에 기대를 걸어보며 저는 다음에 더 유익한 주제로 찾아뵙겠습니다. 감사합니다!
2023.12.25 - [AI 논문 분석] - FERRET: 이미지에서 무엇이든 찾아서 표현하는 애플의 언어 모델
FERRET: 이미지에서 무엇이든 찾아서 표현하는 애플의 언어 모델
안녕하세요. 오늘은 애플이 2023년 10월에 발표한 "FERRET: REFER AND GROUND ANYTHING ANYWHERE AT ANY GRANULARITY"라는 논문에 대해 자세히 알아보겠습니다. 이 논문은 이미지 내에서 어떤 대상이든 어디서든 참
fornewchallenge.tistory.com
'AI 논문 분석' 카테고리의 다른 글
| Mobile ALOHA: 저렴한 전신 원격운전 양손 조작 학습 로봇 (6) | 2024.01.08 |
|---|---|
| Mixtral-8x7B, MoE 언어 모델의 고속 추론 혁신 기술 (2) | 2024.01.04 |
| FERRET: 이미지에서 무엇이든 찾아서 표현하는 애플의 언어 모델 (0) | 2023.12.25 |
| VideoPoet: 구글의 제로샷(Zero-Shot) 비디오 생성 대규모 언어 모델 (4) | 2023.12.23 |
| [AI 논문 리뷰] 대규모 언어 모델을 위한 애플의 메모리 최적화 기술 (0) | 2023.12.22 |



