안녕하세요! 오늘은 대규모 언어모델 애플리케이션 개발 도구인 Ollama와 Langchain, 데이터 시각화 및 웹 애플리케이션을 위한 오픈 소스 라이브러리 Streamlit을 활용해서 대규모 언어 모델 Mistral 7B와 로컬에서 PDF로 대화하는 프로젝트를 진행해 보겠습니다. 이 프로젝트의 출처는 깃 허브의 "Local PDF Chat Application with Mistral 7B LLM, Langchain, Ollama, and Streamlit"이며, 모든 스크린샷은 직접 실행한 것입니다. 그럼 같이 시작해 보실까요?

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
프로젝트 개요 및 Langchain
이 프로젝트는 LangChain 라이브러리를 사용하여 PDF문서와 관련된 질문에 대답하는 웹기반 챗봇을 구현합니다. Ollama는 대규모 언어모델 Mistral 7B를 웹에서 서비스할 수 있도록 구동하며, Stramlit은 웹 사용자 인터페이스를 만듭니다. 사용자가 업로드한 PDF 파일(200MB 이하)의 텍스트는 청크(chunk)로 나누어진 후 벡터화 과정을 거쳐 ChromaDB 벡터 스토어에 저장되고, 사용자 쿼리벡터와 유사도를 측정하여 결과값을 반환하게 됩니다.
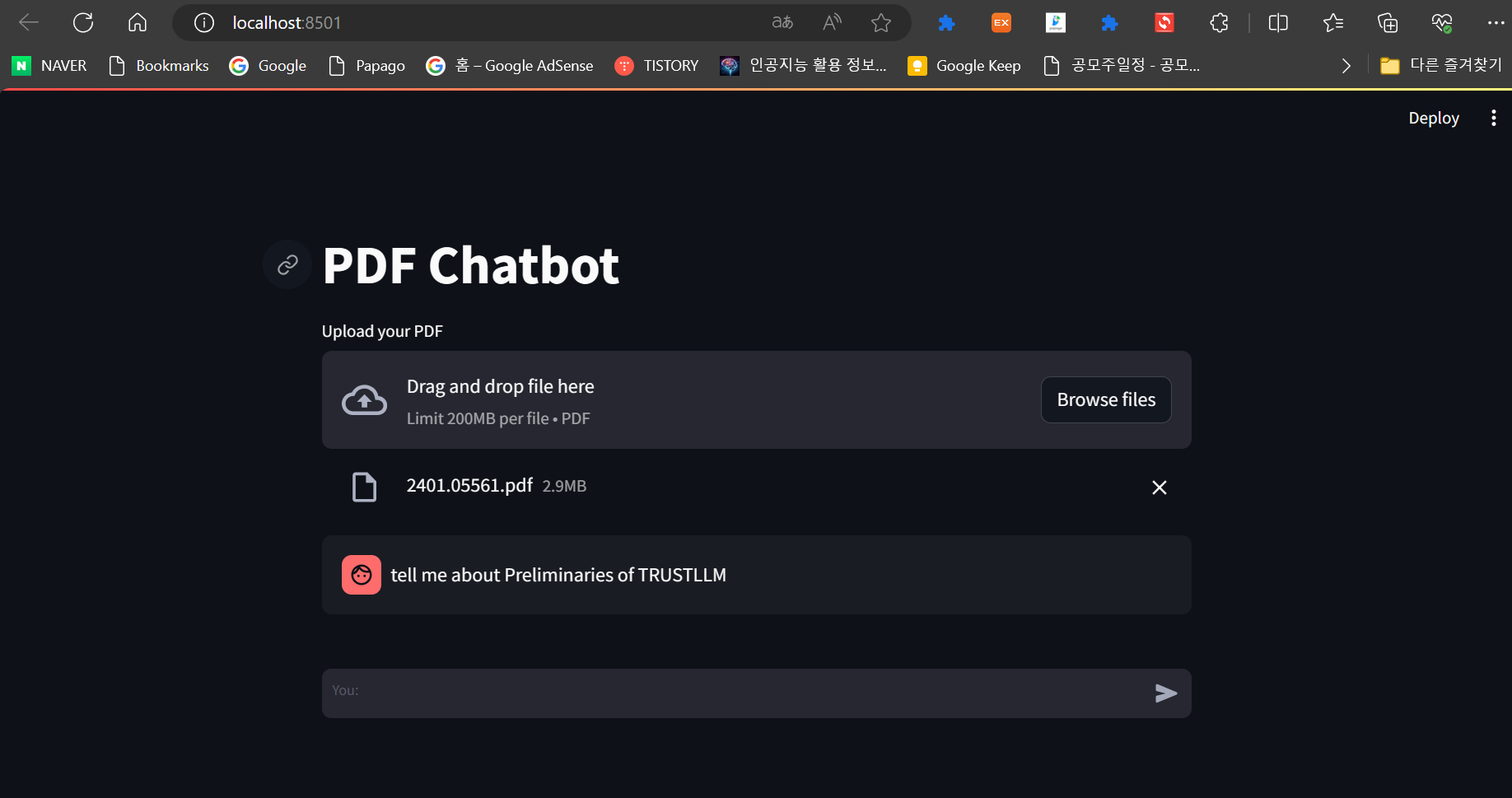
LangChain은 자연어 처리와 관련된 다양한 작업을 수행하는 데 도움이 되는 파이썬 라이브러리입니다. 다음은 LangChain의 주요 기능들에 대한 설명입니다:
- 1. 문장 분리 (Sentence Splitting): LangChain은 텍스트를 문장 단위로 분리하는 기능을 제공합니다. 이를 통해 문장 단위로 텍스트를 처리하고 분석할 수 있습니다.
- 2. 토큰화 (Tokenization): 텍스트를 단어 또는 토큰으로 분리하는 작업을 토큰화라고 합니다. LangChain은 이를 수행하는 다양한 토크나이저를 제공합니다. 공백에 기반한 토크나이저, 형태소 분석기 등을 사용할 수 있습니다.
- 3. 개체명 인식 (Named Entity Recognition): LangChain은 다양한 개체명 인식 모델과 알고리즘을 제공하여 텍스트에서 사람, 장소, 날짜 등의 다양한 유형의 개체를 인식할 수 있습니다.
- 4. 감성 분석 (Sentiment Analysis): LangChain은 감성 분석 모델을 제공하여 텍스트의 긍정적인, 부정적인 또는 중립적인 감성을 파악할 수 있습니다.
- 5. 토픽 모델링 (Topic Modeling): 텍스트에서 주제를 추출하는 작업을 토픽 모델링이라고 합니다. LangChain은 텍스트의 주요 주제를 찾아내는 다양한 토픽 모델링 알고리즘을 제공합니다. 이를 통해 텍스트 데이터의 구조와 주요 주제를 파악할 수 있습니다.
- 6. 문서 유사도 (Document Similarity): LangChain은 다양한 문서 유사도 측정 알고리즘을 제공하여 두 개 문서 간의 유사도를 계산할 수 있습니다.
- 7. 질의 응답 (Question Answering): LangChain은 다양한 질의 응답 모델과 알고리즘을 제공하여 텍스트 데이터에서 사용자의 질문에 대한 정확하고 의미 있는 답변을 생성할 수 있습니다.
LangChain은 이 외에도 다양한 자연어 처리 작업을 지원하며, 확장 가능한 구조로 설계되어 새로운 작업이나 모델을 통합하기도 용이합니다. LangChain은 파이썬 프로그래머에게 강력하고 유연한 자연어 처리 도구로서 많은 도움을 줄 수 있는 라이브러리입니다.
환경설정 및 종속성 설치
다음은 환경설정 및 종속성 설치단계입니다. 이번 프로젝트는 대규모 언어 모델 활용도구인 Ollama의 사용을 위해 가상환경 생성과 활성화 모두 WSL(Windows Subsystem for Linux) 프롬프트에서 진행하였으며, WSL 프롬프트에서 가상환경 생성은 "python3.11 -m venv myenv", 활성화는 "source myenv/bin/activate" 명령어를 입력하면 됩니다.
종속성 설치는 아래에 텍스트 내용을 복사해서 원하는 폴더에 requirements.txt라는 이름으로 파일을 만든 다음 가상환경이 활성화된 WSL 프롬프트에서 "pip install -r requirements.txt" 명령어로 종속성을 설치해 줍니다.
langchain==0.0.320
streamlit==1.28.0
chromadb==0.4.14
pypdf==3.17.4
종속성 설치에 포함된 각 라이브러리에 대한 간단한 설명은 다음과 같습니다.
- langchain (버전: 0.0.320): 언어 처리와 관련된 다양한 기능을 제공하는 파이썬 라이브러리입니다. 문서 로딩, 텍스트 분할, 문맥 이해, 검색 기능 등을 포함하고 있습니다. 이를 통해 자연어 처리 및 대화형 시스템 구축에 도움을 줄 수 있습니다.
- streamlit (버전: 1.28.0): 데이터 과학 및 웹 애플리케이션 개발을 위한 사용자 친화적인 프레임워크입니다. 사용자가 데이터 처리, 시각화, 모델 훈련 등을 손쉽게 할 수 있도록 도와줍니다. 특히, 대화형 웹 애플리케이션을 빠르게 구축할 수 있는 기능이 제공됩니다.
- chromadb (버전: 0.4.14): 텍스트 문서와 관련된 정보를 저장하고 검색할 수 있는 데이터베이스입니다. 이 라이브러리를 사용하여 텍스트 문서의 내용을 구조화하고 색인화할 수 있습니다. 검색 기능을 통해 문서를 효율적으로 탐색할 수 있습니다.
- pypdf (버전: 3.17.4): 파이썬에서 PDF 파일을 처리하기 위한 라이브러리입니다. 이 라이브러리를 사용하여 PDF 파일의 내용을 읽고 조작할 수 있습니다. 특히, 텍스트 추출, 페이지 추출 등의 작업에 사용될 수 있습니다.
각 라이브러리는 다양한 기능과 기능을 제공하여 파이썬 개발자들이 언어 처리, 대화형 시스템, 데이터 시각화, PDF 파일 처리 등 다양한 작업을 수행할 수 있도록 도와줍니다.
Mistral:instruct 모델을 다운로드하기 위해서는 Ollama가 설치된 WSL 프롬프트 상에서 "Ollama run mistral:instruct" 명령어를 실행하면 자동으로 아래 화면과 같이 다운로드됩니다. "instruct"라는 용어는 일반적으로 지시사항, 명령에 관련된 텍스트를 이해하고 처리하는 모델을 나타냅니다.

대규모 언어 모델 활용도구 Ollama의 설치방법은 아래 링크를 참고하시기 바랍니다.
2023.12.15 - [대규모 언어모델] - Ollama를 활용한 대규모 언어 모델 웹 인터페이스 만들기: Mistral 7B와의 대화
Ollama를 활용한 대규모 언어 모델 웹 인터페이스 만들기: Mistral 7B와의 대화
안녕하세요. 오늘은 내 컴퓨터에서 웹 인터페이스로 최신 언어모델과 대화하는 프로젝트에 도전해 보겠습니다. 이 블로그에서는 Ollama라는 오픈소스 도구를 이용해서 최신 인기 대규모 언어모
fornewchallenge.tistory.com
파이썬 코드 실행
다음은 코드 실행단계입니다. 코드를 실행하기 전 WSL 프롬프트 상에서 "ollama serve" 명령어를 입력하여 ollama를 기동 합니다. http://127.0.0.1:11434의 주소에서 ollama가 실행되고 있는지 확인합니다.
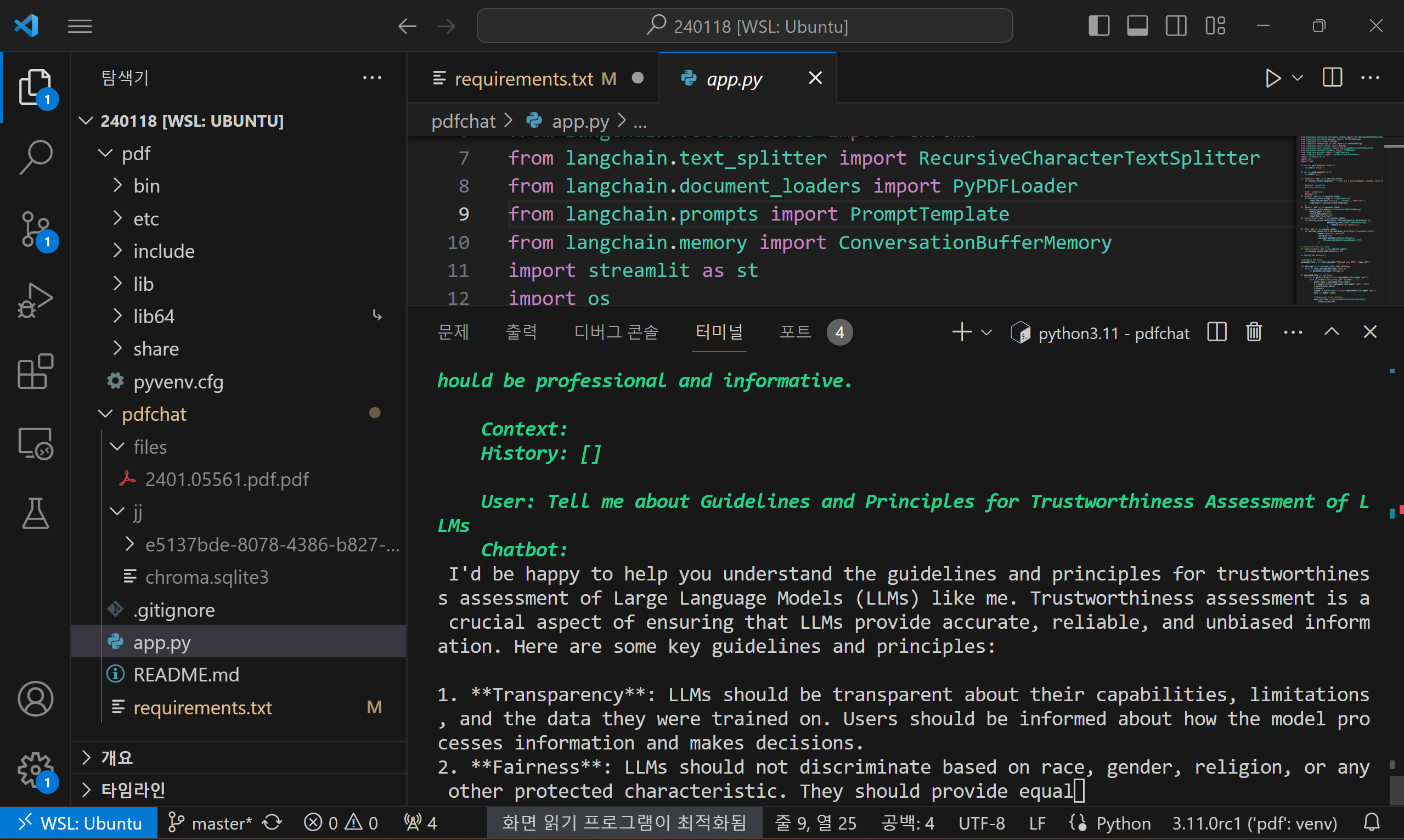
이 코드는 LangChain 라이브러리를 사용하여 PDF 문서와 관련된 질문에 대해 사용자를 도와주는 챗봇을 구현하는 파이썬 스크립트입니다. 코드 실행 명령어는 "streamlit run app.py"이며, 코드의 동작순서는 다음과 같습니다.
- 1. 필요한 모듈 가져오기: 코드는 LangChain 라이브러리뿐만 아니라 `streamlit`, `os`, `time` 등의 표준 파이썬 라이브러리도 가져옵니다.
- 2. 환경 설정하기: 코드는 "files"와 "jj"라는 두 개의 디렉토리를 생성합니다. 이미 해당 디렉토리가 없는 경우에만 생성됩니다. 이 디렉토리는 업로드된 PDF 파일과 벡터 스토어의 지속적인 데이터를 저장하는 데 사용됩니다.
- 3. 세션 상태 초기화: 코드는 `st.session_state` 사전에 특정 변수(`template`, `prompt`, `memory`, `vectorstore`, `llm`, `chat_history`)가 있는지 확인합니다. 없는 경우 기본값으로 초기화합니다.
- 4. 챗봇 인터페이스 생성: 코드는 `streamlit` 라이브러리를 사용하여 챗봇의 웹 기반 사용자 인터페이스를 생성합니다. 제목을 표시하고 사용자가 PDF 파일을 업로드할 수 있는 파일 업로더를 제공합니다.
- 5. 채팅 기록 처리: 코드는 `st.session_state.chat_history` 리스트에 저장된 채팅 기록을 반복문을 통해 확인하고, `st.chat_message` 함수를 사용하여 각 메시지를 표시합니다.
- 6. 업로드된 PDF 파일 처리: PDF 파일이 업로드되면 코드는 "files" 디렉토리에 파일이 이미 존재하는지 확인합니다. 존재하지 않는 경우, 업로드된 파일을 "files" 디렉토리에 저장하고 추가 처리를 진행합니다.
- 7. 텍스트 분할 및 벡터 스토어 생성: 코드는 LangChain 라이브러리를 사용하여 문서를 더 작은 텍스트 청크로 나누기 위해 `RecursiveCharacterTextSplitter` 클래스를 사용합니다. 그런 다음 `Chroma.from_documents` 메서드를 사용하여 텍스트 청크를 벡터 표현으로 변환합니다. 이때 `OllamaEmbeddings` 모델을 사용합니다.
- 8. QA 체인 초기화: 코드는 LangChain 라이브러리를 사용하여 질문-답변(QA) 체인을 초기화합니다. `RetrievalQA.from_chain_type` 메서드를 사용하고, LLM, 리트리버 및 기타 필요한 매개변수를 제공합니다.
- 9. 사용자 입력 및 챗봇 응답: 코드는 `st.chat_input` 함수를 사용하여 사용자 입력을 기다립니다. 사용자가 질문을 제출하면 사용자 메시지를 채팅 기록에 추가하고 `st.chat_message`를 사용하여 표시합니다. 그런 다음 `st.session_state.qa_chain`을 사용하여 사용자 입력을 QA 체인에 전달하고, 챗봇이 응답을 생성하는 동안 타이핑 애니메이션을 표시합니다. 응답은 글자별로 점진적으로 표시되어 타이핑을 모방합니다. 메시지는 채팅 기록에도 추가됩니다.
- 10. PDF 파일이 업로드되지 않은 경우 처리: - PDF 파일이 업로드되지 않은 경우, 코드는 PDF 파일을 업로드하라는 메시지하시라는 메시지를 표시합니다.
위와 같은 동작으로 챗봇 인터페이스를 설정하고 사용자가 PDF 파일을 업로드하도록 하며, 파일을 처리하고 PDF 내용을 기반으로 사용자 질문에 대한 응답을 제공합니다.
from langchain.chains import RetrievalQA
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain.callbacks.manager import CallbackManager
from langchain.llms import Ollama
from langchain.embeddings.ollama import OllamaEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import PyPDFLoader
from langchain.prompts import PromptTemplate
from langchain.memory import ConversationBufferMemory
import streamlit as st
import os
import time
if not os.path.exists('files'):
os.mkdir('files')
if not os.path.exists('jj'):
os.mkdir('jj')
if 'template' not in st.session_state:
st.session_state.template = """You are a knowledgeable chatbot, here to help with questions of the user. Your tone should be professional and informative.
Context: {context}
History: {history}
User: {question}
Chatbot:"""
if 'prompt' not in st.session_state:
st.session_state.prompt = PromptTemplate(
input_variables=["history", "context", "question"],
template=st.session_state.template,
)
if 'memory' not in st.session_state:
st.session_state.memory = ConversationBufferMemory(
memory_key="history",
return_messages=True,
input_key="question")
if 'vectorstore' not in st.session_state:
st.session_state.vectorstore = Chroma(persist_directory='jj',
embedding_function=OllamaEmbeddings(
model="mistral:instruct")
)
if 'llm' not in st.session_state:
st.session_state.llm = Ollama(base_url="http://localhost:11434",
model="mistral:instruct",
verbose=True,
callback_manager=CallbackManager(
[StreamingStdOutCallbackHandler()]),
)
# Initialize session state
if 'chat_history' not in st.session_state:
st.session_state.chat_history = []
st.title("PDF Chatbot")
# Upload a PDF file
uploaded_file = st.file_uploader("Upload your PDF", type='pdf')
for message in st.session_state.chat_history:
with st.chat_message(message["role"]):
st.markdown(message["message"])
if uploaded_file is not None:
if not os.path.isfile("files/"+uploaded_file.name+".pdf"):
with st.status("Analyzing your document..."):
bytes_data = uploaded_file.read()
f = open("files/"+uploaded_file.name+".pdf", "wb")
f.write(bytes_data)
f.close()
loader = PyPDFLoader("files/"+uploaded_file.name+".pdf")
data = loader.load()
# Initialize text splitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1500,
chunk_overlap=200,
length_function=len
)
all_splits = text_splitter.split_documents(data)
# Create and persist the vector store
st.session_state.vectorstore = Chroma.from_documents(
documents=all_splits,
embedding=OllamaEmbeddings(model="mistral")
)
st.session_state.vectorstore.persist()
st.session_state.retriever = st.session_state.vectorstore.as_retriever()
# Initialize the QA chain
if 'qa_chain' not in st.session_state:
st.session_state.qa_chain = RetrievalQA.from_chain_type(
llm=st.session_state.llm,
chain_type='stuff',
retriever=st.session_state.retriever,
verbose=True,
chain_type_kwargs={
"verbose": True,
"prompt": st.session_state.prompt,
"memory": st.session_state.memory,
}
)
# Chat input
if user_input := st.chat_input("You:", key="user_input"):
user_message = {"role": "user", "message": user_input}
st.session_state.chat_history.append(user_message)
with st.chat_message("user"):
st.markdown(user_input)
with st.chat_message("assistant"):
with st.spinner("Assistant is typing..."):
response = st.session_state.qa_chain(user_input)
message_placeholder = st.empty()
full_response = ""
for chunk in response['result'].split():
full_response += chunk + " "
time.sleep(0.05)
# Add a blinking cursor to simulate typing
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
chatbot_message = {"role": "assistant", "message": response['result']}
st.session_state.chat_history.append(chatbot_message)
else:
st.write("Please upload a PDF file.")
다음 화면은 코드를 실행하고, Trust LLM 관련 논문을 업로드하여 질의응답을 진행한 화면입니다.
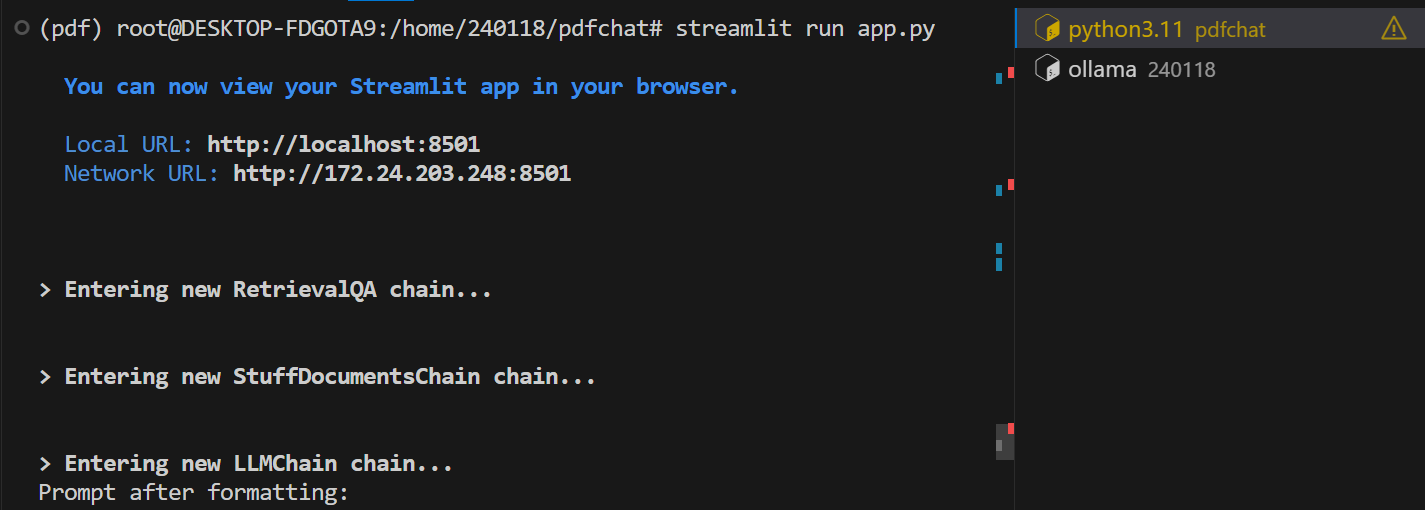
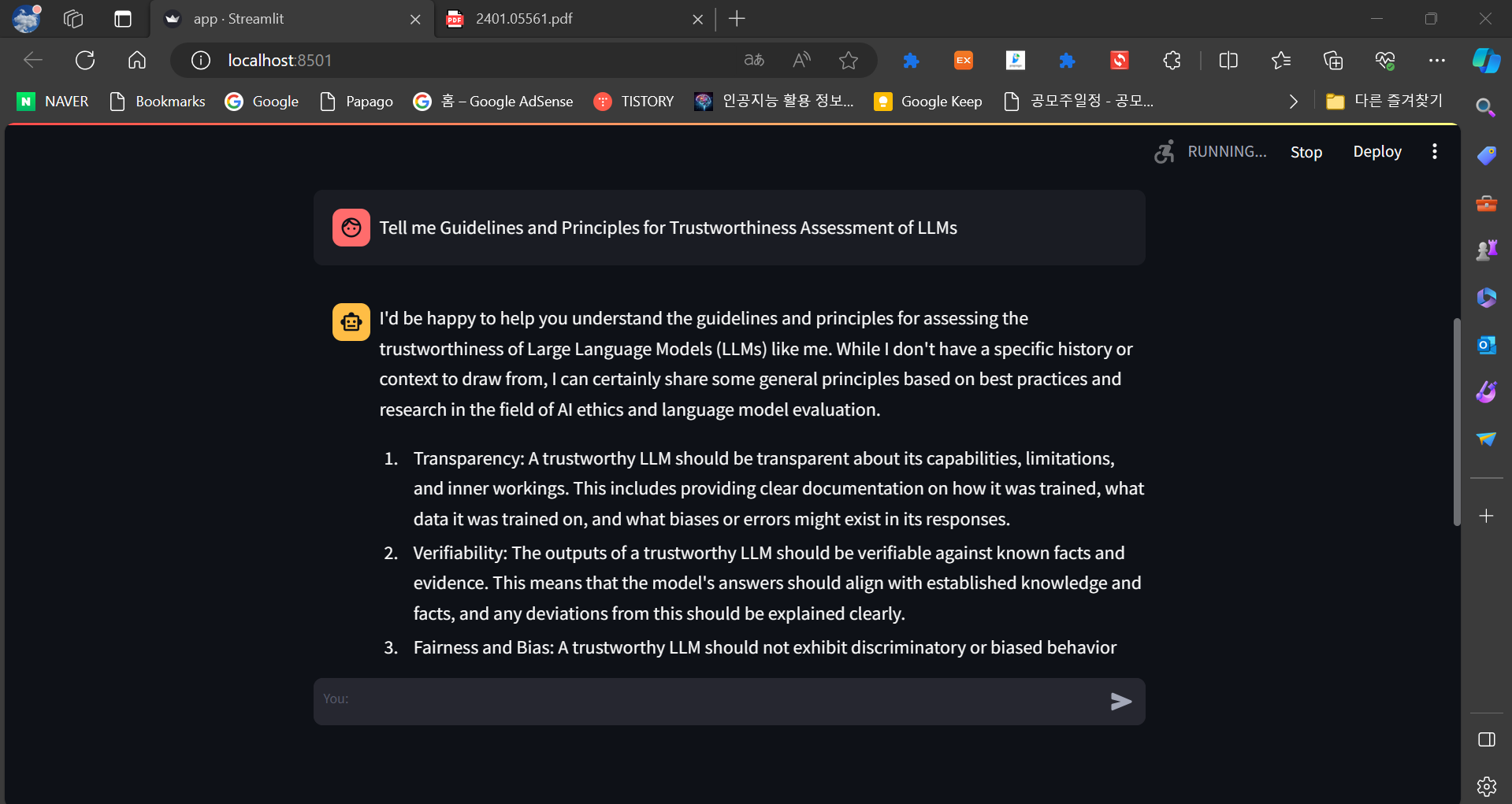
저와 같은 LLM의 신뢰성 평가를 위한 지침과 원칙을 이해하는 데 도움을 드릴 수 있다면 기꺼이 도와드리겠습니다.
신뢰성 평가는 LLM이 정확하고, 신뢰할 수 있고, 편견이 없는 정보를 제공하도록 보장하는 중요한 측면입니다.
여기 몇 가지 주요 지침과 원칙이 있습니다.
1. 투명성: LLM은 그들의 능력, 한계 및 그들이 훈련 받은 데이터에 대해 투명해야 합니다. 사용자는 모델이 어떻게
정보를 처리하고 결정을 내리는지에 대해 알아야 합니다.
2. 공정성: LLM은 인종, 성별, 종교 또는 다른 보호된 특성에 따라 차별해서는 안 됩니다. 배경에 관계없이 모든 사용자에게
동등한 대우를 제공해야 합니다.
3. 정확성: LLM은 정확하고 진실한 정보를 제공해야 합니다. 그들은 사실과 허구를 구별하고 신뢰할 수 있는 대답을
제공할 수 있어야 합니다.
4. 맥락 이해: LLM은 자신이 사용되고 있는 맥락을 이해해야 합니다. 그들은 적절한 응답을 제공하기 위해 사전 지식과
상식을 사용할 수 있어야 합니다.
5. 안전: LLM은 사용자 또는 사회에 위협을 가해서는 안 됩니다. 그들은 해롭거나 공격적인 내용을 제공해서는 안 되며
오용을 방지하도록 설계되어야 합니다.
6. 개인 정보 보호: LLM은 사용자의 개인 정보를 존중해야 합니다. 사용자의 동의 없이 민감한 정보를 수집하거나
공유해서는 안 됩니다.
7. 책임: LLM은 자신들의 행동에 대해 책임을 져야 합니다. 개발자와 사용자는 모델의 반응의 출처를 추적하고 그것이
어떻게 생성되었는지 이해할 수 있어야 합니다.
8. 지속적인 개선: LLM은 새로운 위협, 편향 및 한계를 해결하기 위해 지속적으로 업데이트되고 개선되어야 합니다. 사용자
피드백으로부터 배우고 변화하는 맥락에 적응하도록 설계되어야 합니다.
9. 설명 가능성: LLM은 자신의 추론 및 의사 결정 과정을 설명할 수 있어야 합니다. 사용자는 모델이 특정 답변이나 권장
사항에 어떻게 도달했는지 이해할 수 있어야 합니다.
10. 윤리적 사용: LLM은 인권 및 문화적 민감성을 존중하여 윤리적으로 사용되어야 합니다. 다른 사람을 조종하거나 속이거나
해를 가하는 데 사용되어서는 안 됩니다.
LLMs는 이러한 지침과 원칙에 따라 사용자의 개인 정보 보호, 안전 및 공정성을 보장하면서 신뢰할 수 있는 정보를 제공할 수 있습니다
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
마치며
이번 프로젝트를 통해 Ollama, Langchain, Streamlit을 활용하여 대규모 언어 모델 Mistral 7B와 로컬에서 PDF와 대화하는 웹 애플리케이션을 구현해 보았습니다. Ollama는 대규모 언어 모델 Mistral 7B를 웹에서 서비스할 수 있도록 구동하며, Streamlit은 웹 사용자 인터페이스를 만듭니다. PDF 파일의 텍스트는 청크로 나누어 벡터화되고 ChromaDB 벡터 스토어에 저장되어 사용자 쿼리에 대한 응답을 생성합니다.
LangChain은 다양한 자연어 처리 작업을 지원하며, 확장 가능한 구조로 설계되어 새로운 작업이나 모델을 통합하기 용이하므로 여러 분야에서 활용할 수 있을 것 같습니다. 여러분도 이번 프로젝트를 통해 대규모 언어 모델을 활용한 웹 기반 챗봇 구현에 대한 기본적인 이해와 실제적인 경험을 쌓는데 도움이 되었기를 바라면서 저는 다음에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.
2024.01.07 - [AI 도구] - 텍스트 임베딩을 이용한 벡터검색 Q&A 시스템 만들기
텍스트 임베딩을 이용한 벡터검색 Q&A 시스템 만들기
안녕하세요! 오늘은 웹에서 사용자의 질문과 가장 유사한 Q&A 데이터셋을 벡터검색해서 유사도와 함께 표시하는 AI기반 Q&A 시스템을 만드는 프로젝트입니다. 기존의 키워드 검색방식은 만족하는
fornewchallenge.tistory.com