안녕하세요. 오늘은 캐릭터의 이미지 한 장만 있으면 원하는 자세로 움직이는 애니메이션 만들 수 있는 Animate Anyone이라는 기술을 발표한 논문에 대해 살펴보겠습니다. 이번 블로그에서는 이미지로부터 일관되고 안정적인 캐릭터 애니메이션을 구현하기 위해 개발된 Animate Anyone 기술의 원리와 구조, 특징 등에 대해서 확인하실 수 있습니다.


논문 개요 및 목적
이 논문의 개요와 목적은 다음과 같습니다.
- 논문 제목 : Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation
- 논문 저자 : Li Hu, Xin Gao, Peng Zhang, Ke Sun, Bang Zhang, Liefeng Bo
- 논문 게재 사이트 : https://arxiv.org/
- 논문 게재일 : 2023년 11월
이 논문의 목적은 캐릭터 이미지를 입력으로 하여 원하는 움직임에 따라 안정적이고 지속적인 캐릭터 애니메이션을 생성하는 새로운 프레임워크인 Animate Anyone을 제안하는 것입니다.


논문의 주요 연구내용
다음은 Animate Anyone의 주요 구성요소에 대한 연구내용입니다.
Animate Anyone은 ReferenceNet, Pose Guider, 시간 모델링이라는 세 가지 주요 구성 요소를 사용하여 캐릭터 이미지를 원하는 포즈 시퀀스에 따라 안정적이고 지속적인 캐릭터 애니메이션을 생성합니다.
- ReferenceNet: 캐릭터의 외관특징을 보존하고, 입력된 이미지의 공간적 세부 정보를 캡처합니다. 일관된 특징 공간에서 입력된 이미지와의 관계를 학습하여 일관성 있는 외관 세부 정보를 보존하는 역할을 합니다. ReferenceNet은 입력된 이미지의 세부 정보를 효과적으로 추출하고 이를 모델의 다른 부분과 일관된 방식으로 결합하여 안정적이고 지속적인 캐릭터 애니메이션 생성에 기여하는 역할을 합니다.
- Pose Guider: 캐릭터의 동작을 안내하는 역할을 합니다. 이는 사용자가 원하는 포즈 시퀀스를 입력하면 입력된 포즈 정보의 다양한 특징을 추출하고 잡음특성과 결합하여 캐릭터 이미지에 반영하며 AI모델이 이를 이해하여 해당 동작을 적용하는 데 도움을 줍니다. Pose Guider는 사용자가 입력한 포즈 정보를 기반으로 캐릭터 이미지에 동작을 안내하여 모션의 안정성을 유지하면서 움직이는 캐릭터 애니메이션을 생성합니다.
- 시간 모델링: 연속된 이미지 프레임 간의 부드러운 전환을 보장하기 위한 접근 방식입니다. 시간 모델링은 템포랄 어텐션을이용하여 연속적인 프레임 간의 관계를 학습하여 모델링하고 이 관계를 사용하여 다음 프레임이 현재 프레임에 어떻게 의존하는지를 이해하고, 예측합니다. 이를 통해 애니메이션 비디오의 깜박임이나 흔들림을 방지하고 자연스러운 흐름을 향상시킵니다.
다음 구성도는 Animate Anyone 기술 간의 상호 연결구조를 나타냅니다. 위 내용을 참고하시면서 보시면 좋을것 같습니다.
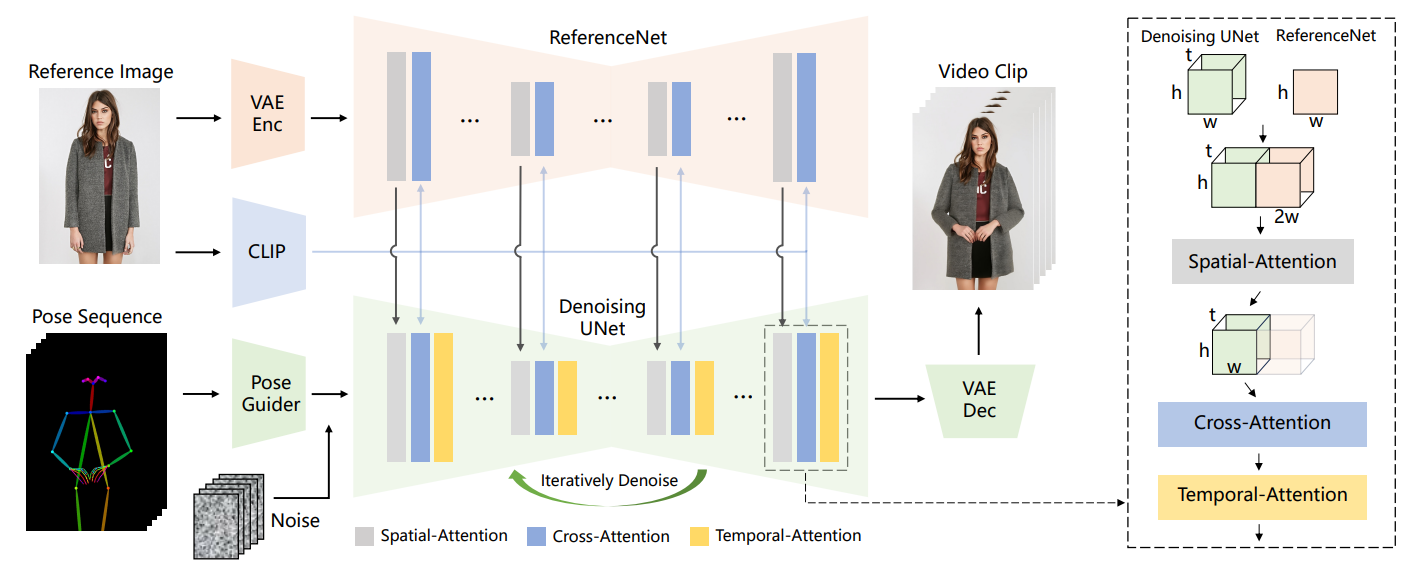
위 구성도에 등장하는 용어에 대한 간단한 설명입니다.
- 크로스 어텐션(Cross-Attention): 크로스 어텐션은 주어진 두 시퀀스 간의 관계를 학습하는 메커니즘입니다. 이 논문에서는 주로 이미지의 세부특징과 포즈의 움직임의 관계를 학습하고 모델링하는 데 활용되었습니다.
- 템포랄 어텐션(Temporal Attention): 템포랄 어텐션은 시간적인 흐름을 고려하여 프레임 간의 관계를 모델링하는 메커니즘입니다. 이 논문에서는 프레임 간의 움직임 일관성을 유지하고 부드러운 애니메이션을 생성하는데 기여합니다.
- 스페이셜 어텐션(Spatial Attention) : 스페이셜 어텐션은 주어진 공간 내에서 중요한 부분에 주목하여 특징을 강조하는 메커니즘입니다. 논문에서 이미지 내의 중요한 부분을 감지하고 강조하는 데 사용됩니다. 캐릭터 이미지의 특정 부분에 주목하여 애니메이션에서의 세부 특징을 보존하고 강조합니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
위 구성도의 Animate Anyone 프로세스를 요약하면,
- 1. 입력된 참조 이미지는 ReferenceNet에서 캐릭터의 외관특징과 세부 정보를 보존하고,
- 2. Pose Guider를 통해 포즈의 특징을 추출하여 이미지와 잡음특성을 결합한 후,
- 3. "U" 형태 구조의 Denoising UNet이라고 하는 신경망구조에서 노이즈를 제거하고 정확한 정보로 복원되며,
- 4. 시간 모델링으로 다중 프레임 간의 관계를 고려하여 시간적 일관성을 보존함으로써,
- 5. 최종적으로 창의적이고 자연스러운 캐릭터 애니메이션을 구현하게 됩니다.
| Animate Anyone으로 구현한 영상 |

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."

논문의 결론 및 전망
본 논문에서는 캐릭터 이미지를 애니메이션 비디오로 변환하는 새로운 프레임워크인 Animate Anyone을 제안했습니다. Animate Anyone은 ReferenceNet, Pose Guider, 시간 모델링 세 가지 주요 혁신기술을 도입하여 캐릭터 이미지의 세밀한 외관 특징을 보존하고, 효율적인 포즈 제어 및 시간 모델링을 구현하였으며, 다양한 캐릭터에 대해 일관되고 안정적인 애니메이션 결과를 생성하는 것으로 나타났습니다.
이미지 한 장으로 캐릭터 애니메이션을 구현하는 기술인 Animate Anyone은 캐릭터 애니메이션 분야의 발전에 크게 기여할 것으로 기대됩니다. Animate Anyone은 가상 캐릭터 제작, 애니메이션 영화 제작, 소셜 미디어 애플리케이션 등 다양한 분야에 적용될 수 있을 것 같습니다.
자고나면 새로운 AI 기술이 등장하는 시대인것 같습니다. 저는 그럼 다음 시간에 더 유익한 정보로 다시 찾아뵙겠습니다. 감사합니다.
2023.11.14 - [AI 논문 요약] - AI 논문 분석 : 생성형 AI 모델 종류 및 특징 정리
AI 논문 분석 : 생성형 AI 모델 종류 및 특징 정리
안녕하세요. 오늘은 AI 분야의 최신 논문을 살펴보는 두 번째 시간으로 최근 등장하고 있는 생성형 AI모델의 종류와 특징을 분석한 논문이 있어서 소개해드리려고 합니다. 생성형 AI의 주요 모델
fornewchallenge.tistory.com
'AI 논문 분석' 카테고리의 다른 글
| AI 논문 분석: 대규모 언어 모델을 활용한 프로그램 탐색, FunSearch (0) | 2023.12.19 |
|---|---|
| AI 논문 분석 : 이미지 애니메이션의 혁신 라이브포토(LivePhoto) (2) | 2023.12.12 |
| AI 논문 요약, '유망 신소재' 38만개 찾은 딥마인드의 AI기술 (2) | 2023.12.01 |
| AI 논문 분석 : 범용인공지능(AGI)의 정의와 수준, 그리고 미래 (0) | 2023.11.28 |
| AI 논문 분석 : LRM, 5초 안에 단일 이미지에서 3D로 (2) | 2023.11.21 |



