안녕하세요! 오늘은 요즘 챗GPT보다 핫한 언어 모델 클로드 3을 이용해서 일러스트를 그려보겠습니다. 앤트로픽의 최신 대형 언어 모델인 클로드 3 모델은 성능과 속도를 고려하여 Haiku, Sonnet 및 Opus라는 세 가지 모델로 구성되어 있으며, 이 중 Opus 모델은 특히 GPT-4나 Gemini와 같은 기존 모델들을 능가하는 성능을 보여줍니다. 이 블로그에서는 Opus 모델과 Stable Diffusion을 활용해서 사용자의 질문에 대한 설명과 일러스트를 그리는 기능을 구현해 보겠습니다.


"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
프로그램 개요
이 블로그에서는 사용자가 질문을 입력하면, 해당 질문에 기반하여 텍스트 응답과 함께 이미지를 생성하여 제공하는 서비스를 구현합니다. 여기에는 다음과 같은 몇 가지 주요 개념이 포함되어 있습니다:
- 인공지능 모델과 API 통합: 코드는 두 가지 주요 AI 기술을 통합하여 기능을 구현합니다. 하나는 클로드 3 Opus 모델이고, 다른 하나는 Stability AI의 Stable Diffusion v1.6 엔진입니다. 이 두 가지 기술을 함께 사용하여 사용자의 질문에 대한 응답을 생성하고 이미지를 생성합니다.
- API 통신: 코드는 HTTP 요청을 사용하여 외부 API와 통신합니다. 사용자가 입력한 질문을 API에 전달하고, API는 해당 질문을 처리하여 이미지를 생성한 후 응답을 제공합니다.
- 텍스트 처리: 사용자가 입력한 질문을 텍스트로 처리하고, 이를 모델에 전달하여 응답을 생성합니다. 이 과정에서 정규식 및 문자열 처리 기술이 사용됩니다. 클로드는 사용자의 질문을 분석하고 이를 텍스트 프롬프트로 변환하여 이미지 생성 엔진에 전달합니다.
- 이미지 생성: Stability AI의 Stable Diffusion 엔진은 텍스트를 입력으로 받아들여 이를 이미지로 변환합니다. 이를 위해 클로드로부터 텍스트 프롬프트를 전달받고, 해당 프롬프트를 이용하여 이미지를 생성합니다.
- 이미지 저장 및 표시: 생성된 이미지는 파일로 저장되고, 그라디오 인터페이스를 통해 사용자에게 제공됩니다. 사용자는 그라디오를 통해 질문을 입력하고, 생성된 이미지와 텍스트 응답을 확인할 수 있습니다.
이 코드는 클로드 3 Opus 모델과 스테이블 디퓨전 API를 통합하여 사용자와의 상호작용을 통해 다양한 형태의 콘텐츠를 생성하고 제공하는 서비스를 구현합니다.
API Key발급 및 환경설정
먼저 클로드 3 Opus를 이용해서 일러스트를 그리기 위해 필요한 앤트로픽 API Key를 발급받아야 하는데요. API Key를 발급받기 위한 자세한 설명은 아래 포스트를 참고하시면 쉽게 확인하실 수 있습니다.
2024.03.06 - [대규모 언어모델] - 클로드(Claude) 3: GPT-4와 제미나이를 뛰어넘은 언어 모델의 등장!
클로드(Claude) 3: GPT-4와 제미나이를 뛰어넘은 언어 모델의 등장!
안녕하세요! 오늘은 3월 4일 발표된 앤트로픽의 최신 대형 언어 모델 클로드(Claude) 3에 대해서 알아보겠습니다. 이번에 발표된 클로드 3 모델 패밀리는 Haiku, Sonnet 및 Opus라는 세 가지 최신 모델로
fornewchallenge.tistory.com
다음으로 Stability AI의 API Key를 발급받기 위해서는 아래 링크를 통해 Stability AI Developer Platform에 가입한 후, 우측 상단 프로필 아이콘을 클릭하시면 Create API Key 버튼을 클릭해서 발급하실 수 있습니다.
https://platform.stability.ai/
Stability AI - Developer Platform
platform.stability.ai
API Key 발급이 완료되면, 다음은 기본 코딩 환경설정 단계입니다. 이 블로그에서 사용한 예제코드의 실행환경은 Windows 11 Pro(23H2), 파이썬 버전 3.11, 코드 에디터는 비주얼 스튜디오 코드(이하 VSC)이며, VSC를 실행하여 "WSL에 연결"을 통해 Windows Subsystem for Linux(WSL)을 사용하여 Linux 환경에 액세스 하도록 구성합니다.
다음은 VSC 명령 프롬프트에서 "python3.11 -m venv myenv"와 "source myenv/bin/activate" 명령어를 통해 가상환경을 생성 및 활성화 한 다음, 아래 명령어로 의존성(dependency)을 설치해 줍니다.
pip install requests anthropic gradio
이 코드는 Python 패키지 관리자인 pip를 사용하여 여러 라이브러리를 설치하는 명령어입니다. 각 라이브러리에 대한 간단한 설명은 다음과 같습니다:
- requests: HTTP 요청을 보내고 응답을 받는 데 사용되는 라이브러리입니다. 웹 페이지에 접근하거나 웹 API와 통신할 때 유용하게 사용됩니다.
- anthropic: 앤트로픽(Anthropic)은 인공지능 연구 및 개발 회사로, 이 라이브러리는 앤트로픽의 서비스 및 제품을 사용하는 데 필요한 기능을 제공합니다. 클로드(Claude)와 같은 앤트로픽의 제품을 사용하기 위해 필요한 라이브러리입니다.
- gradio: 인터랙티브한 머신러닝 및 딥러닝 모델을 쉽게 구축하고 공유할 수 있는 라이브러리입니다. 그라디오를 사용하면 웹에서 모델을 시각화하고 사용자와 상호 작용할 수 있는 사용자 정의 UI를 만들 수 있습니다.
이 명령어를 실행하여 위의 라이브러리를 모두 설치하면, 해당 라이브러리들을 사용하여 웹 요청, 앤트로픽의 서비스 및 제품 사용, 머신러닝 모델의 구축 및 시각화 등 다양한 작업을 수행할 수 있습니다.
예제코드 실행
이 블로그 예제코드의 출처는 깃허브 앤트로픽 쿡북이며, 사용자 프롬프트를 일부 수정하고, Gradio 인터페이스를 추가하였습니다. 쿡북에는 이 블로그 예제 이외에도 다양한 활용사례를 확인하실 수 있습니다.
https://github.com/anthropics/anthropic-cookbook
GitHub - anthropics/anthropic-cookbook: A collection of notebooks/recipes showcasing some fun and effective ways of using Claude
A collection of notebooks/recipes showcasing some fun and effective ways of using Claude. - anthropics/anthropic-cookbook
github.com
이 블로그의 예제코드는 다음과 같은 구성으로 작성되어 있습니다.
- STABILITY 및 ANTHROPIC_API_KEY 설정: API 키를 설정합니다.
- gen_image(prompt, height, width, num_samples) 함수: Stability AI API를 사용하여 주어진 텍스트 프롬프트를 기반으로 이미지를 생성하는 함수입니다. 함수는 API를 호출하고 생성된 이미지를 base64 형식으로 반환합니다.
- save_image(b64, filename) 함수: base64 형식의 이미지를 받아서 디코딩하고 지정된 파일 이름으로 이미지를 저장하는 함수입니다.
- llustrator_claude(prompt) 함수: Claude의 작동을 제어하는 함수로, 사용자에게 이미지 생성을 요청하는 프롬프트를 정의하고, 주어진 프롬프트를 기반으로 이미지를 생성하여 반환합니다.
- parse_response_and_gen_image(claude_response) 함수: Claude의 응답을 파싱하고 이미지 생성을 시작하는 함수입니다. 사용자가 이미지 생성을 요청한 경우, 프롬프트를 추출하고 해당 프롬프트를 사용하여 이미지를 생성합니다.
- ask_question_and_display_image(question) 함수: 사용자의 질문을 받아들이고, 이를 기반으로 이미지 생성을 Claude에게 지시하는 함수입니다. 생성된 이미지는 파일로 저장되고, 텍스트 응답과 함께 파일 이름이 반환됩니다.
- Gradio를 사용한 웹 인터페이스: Gradio를 사용하여 간단한 웹 인터페이스를 생성하고, 사용자의 질문을 받아들이고 이미지 및 텍스트 응답을 표시합니다.
이 코드는 사용자가 질문을 하고 그에 따른 이미지 생성 및 텍스트 응답을 받을 수 있는 인터랙티브한 방식으로 작동합니다. Gradio를 통해 사용자가 직접 질문을 입력하고 그에 대한 결과를 즉시 확인할 수 있습니다.
import os
import re
import requests
import anthropic
import gradio as gr
from base64 import b64decode
STABILITY_API_KEY = "발급받은 API Key" # Stability API key goes here
ANTHROPIC_API_KEY = "발급받은 API Key" # Anthropic API key goes here
MODEL_NAME = "claude-3-opus-20240229"
CLIENT = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
# Create a directory to store images if it doesn't exist
if not os.path.exists("/home/rg3270/anthropic-cookbook/images"):
os.makedirs("/home/rg3270/anthropic-cookbook/images")
def gen_image(prompt, height=1024, width=1024, num_samples=1):
engine_id = "stable-diffusion-v1-6"
api_host = 'https://api.stability.ai'
response = requests.post(
f"{api_host}/v1/generation/{engine_id}/text-to-image",
headers={
"Content-Type": "application/json",
"Accept": "application/json",
"Authorization": f"Bearer {STABILITY_API_KEY}"
},
json={
"text_prompts": [
{
"text": prompt,
}
],
"cfg_scale": 7,
"height": height,
"width": width,
"samples": num_samples,
"steps": 30,
},
)
if response.status_code != 200:
raise Exception("Non-200 response: " + str(response.text))
data = response.json()
return data['artifacts'][0]['base64']
def save_image(b64, filename):
with open(filename, "wb") as f:
f.write(b64decode(b64))
def illustrator_claude(prompt):
# 이미지 생성 시스템 프롬프트 정의
image_gen_system_prompt = ("You are Claude, a helpful, honest, harmless AI assistant. "
"One special thing about this conversation is that you have access to an image generation API, "
"so you may create images for the user if they request you do so, or if you have an idea "
"for an image that seems especially pertinent or profound. However, it's also totally fine "
"to just respond to the human normally if that's what seems right! If you do want to generate an image, "
"write '<function_call>create_image(PROMPT)</function_call>', replacing PROMPT with a description of the image you want to create.")
image_gen_system_prompt += """
Here is some guidance for getting the best possible images:
<image_prompting_advice>
Rule 1. Make Your Stable Diffusion Prompts Clear, and Concise
Successful AI art generation in Stable Diffusion relies heavily on clear and precise prompts. It's essential to craft problem statements that are both straightforward and focused.
Clearly written prompts acts like a guide, pointing the AI towards the intended outcome. Specifically, crafting prompts involves choosing words that eliminate ambiguity and concentrate the AI's attention on producing relevant and striking images.
Conciseness in prompt writing is about being brief yet rich in content. This approach not only fits within the technical limits of AI systems but ensures each part of the prompt contributes meaningfully to the final image. Effective prompt creation involves boiling down complex ideas into their essence.
Prompt Example:
"Minimalist landscape, vast desert under a twilight sky."
This prompt exemplifies how a few well-chosen words can paint a vivid picture. The terms 'minimalist' and 'twilight sky' work together to set a specific mood and scene, demonstrating effective prompts creation with brevity.
Another Example:
"Futuristic cityscape, neon lights, and towering skyscrapers."
Here, the use of descriptive but concise language creates a detailed setting without overwhelming the AI. This example showcases the importance of balancing detail with succinctness in prompt structuring methods.
Rule 2. Use Detailed Subjects and Scenes to Make Your Stable Diffusion Prompts More Specific
Moving into detailed subject and scene description, the focus is on precision. Here, the use of text weights in prompts becomes important, allowing for emphasis on certain elements within the scene.
Detailing in a prompt should always serve a clear purpose, such as setting a mood, highlighting an aspect, or defining the setting. The difference between a vague and a detailed prompt can be stark, often leading to a much more impactful AI-generated image. Learning how to add layers of details without overwhelming the AI is crucial.
Scene setting is more than just describing physical attributes; it encompasses emotions and atmosphere as well. The aim is to provide prompts that are rich in context and imagery, resulting in more expressive AI art.
Prompt Example:
"Quiet seaside at dawn, gentle waves, seagulls in the distance."
In this prompt, each element adds a layer of detail, painting a serene picture. The words 'quiet', 'dawn', and 'gentle waves' work cohesively to create an immersive scene, showcasing the power of specific prompts crafting.
Another Example:
"Ancient forest, moss-covered trees, dappled sunlight filtering through leaves."
This prompt is rich in imagery and detail, guiding the AI to generate an image with depth and character. It illustrates how detailed prompts can lead to more nuanced and aesthetically pleasing results.
Rule 3. Contextualizing Your Prompts: Providing Rich Detail Without Confusion
In the intricate world of stable diffusion, the ability to contextualize prompts effectively sets apart the ordinary from the extraordinary. This part of the stable diffusion guide delves into the nuanced approach of incorporating rich details into prompts without leading to confusion, a pivotal aspect of the prompt engineering process.
Contextualizing prompts is akin to painting a picture with words. Each detail added layers depth and texture, making AI-generated images more lifelike and resonant. The art of specific prompts crafting lies in weaving details that are vivid yet coherent.
For example, when describing a scene, instead of merely stating:
"a forest."
one might say,
"a sunlit forest with towering pines and a carpet of fallen autumn leaves."
Other Prompt Examples:
"Starry night, silhouette of mountains against a galaxy-filled sky."
This prompt offers a clear image while allowing room for the AI’s interpretation, a key aspect of prompt optimization. The mention of 'starry night' and 'galaxy-filled sky' gives just enough context without dictating every aspect of the scene.
Rule 4. Do Not Overload Your Prompt Details
While detail is desirable, overloading prompts with excessive information can lead to ambiguous results. This section of the definitive prompt guide focuses on how to strike the perfect balance.
Descriptive Yet Compact: The challenge lies in being descriptive enough to guide the AI accurately, yet compact enough to avoid overwhelming it. For instance, a prompt like, 'A serene lake, reflecting the fiery hues of sunset, bordered by shadowy hills' paints a vivid picture without unnecessary verbosity.
Precision in language is key in this segment of the stable diffusion styles. It's about choosing the right words that convey the most with the least, a skill that is essential in prompt optimization.
For example, instead of using:
"a light wind that can barely be felt but heard"
You can make it shorter:
whispering breeze
More Prompt Examples:
Sample prompt: "Bustling marketplace at sunset, vibrant stalls, lively crowds."
By using descriptive yet straightforward language, this prompt sets a vivid scene of a marketplace without overcomplicating it. It's an example of how well-structured prompts can lead to dynamic and engaging AI art.
</image_prompting_advice>
"""
claude_response = CLIENT.messages.create(
system=image_gen_system_prompt,
model=MODEL_NAME,
max_tokens=1024,
messages=[
{"role": "user", "content": prompt}
],
).content[0].text
return parse_response_and_gen_image(claude_response)
def parse_response_and_gen_image(claude_response):
if "<function_call>" in claude_response:
image_prompt = claude_response.split('<function_call>create_image(')[1].split(')</function_call>')[0].replace('"', '')
base64 = gen_image(image_prompt)
else:
image_prompt, base64 = None, None
function_free_claude_response = re.sub(r'<function_call>.*</function_call>', '', claude_response)
# return the image_prompt too
return (function_free_claude_response, image_prompt, base64)
def ask_question_and_display_image(question):
function_free_response, image_prompt, b64 = illustrator_claude(question)
image_filename = "/home/rg3270/anthropic-cookbook/images/illustration_image.png"
save_image(b64, image_filename)
return function_free_response, image_filename # Return the filename instead of display.Image object
# Create a Gradio interface
iface = gr.Interface(
fn=ask_question_and_display_image,
inputs=gr.components.Textbox(lines=5, placeholder="Enter your question here..."),
outputs=["text", "image"],
title="Claude the Illustrator",
description="Ask Claude a question and see an image generated based on the question.",
)
# Launch the interface
iface.launch()
위 파이썬 예제 코드를 복사해서 파일을 저장한 후 실행하면 http://127.0.0.1:7860/의 주소에서 웹페이지가 열립니다.
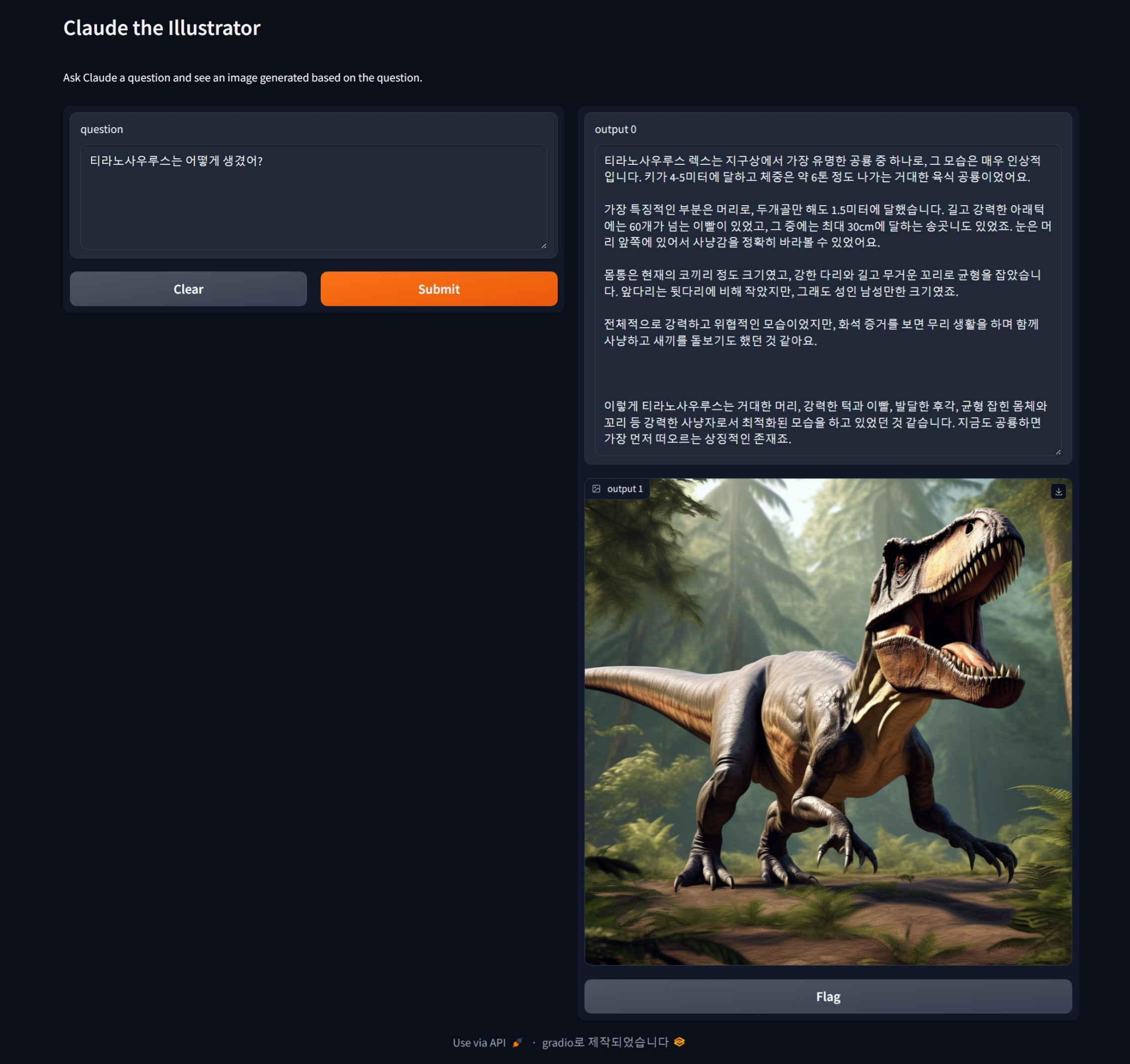
먼저, 저는 티라노 사우루스가 어떻게 생겼는지 물어보았는데 아래 화면과 같이 설명과 일러스트를 그려주었습니다.
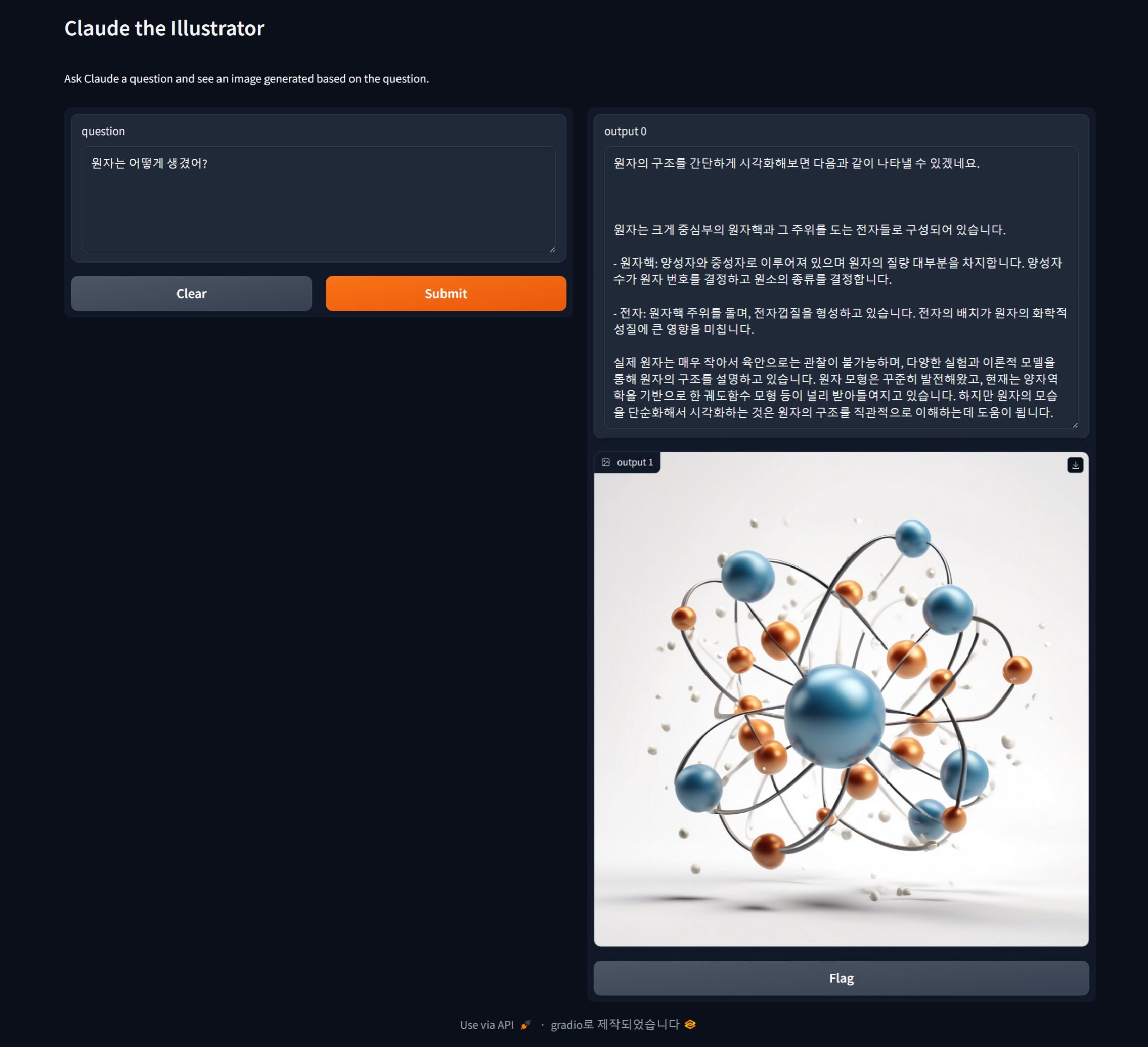
다음은 원자의 모양이 어떻게 생겼는지 물어보니, 클로드는 아래와 같이 원자의 구조를 설명하고 일러스트를 그렸습니다.
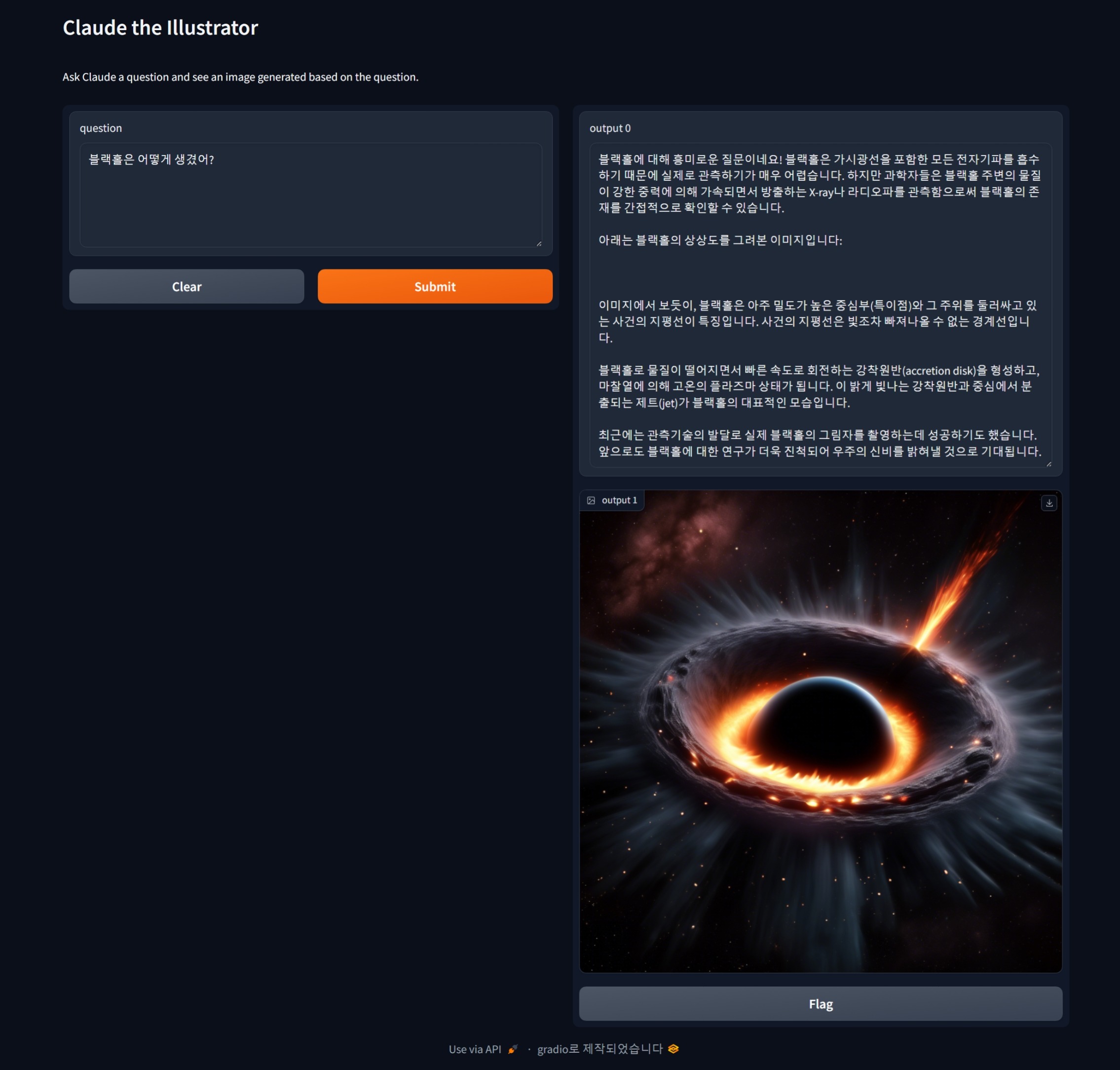
다음은 마지막으로 블랙홀 질문에 대한 설명과 일러스트입니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
맺음말
오늘 블로그에서는 클로드 3 Opus와 Stable Diffusion 엔진을 활용하여 일러스트를 그려보았습니다. 이번 예제를 통해 앤트로픽의 최신 대형 언어 모델이 얼마나 다양한 주제에 대해 풍부한 설명과 함께 원하는 이미지를 생성할 수 있는지 확인할 수 있었습니다. 클로드 3은 GPT-4나 Gemini와 같은 기존 모델들을 능가하는 성능을 자랑하며, 다양한 예술적 창작뿐만 아니라 일상적인 질문에도 뛰어난 대답을 제공합니다.
이 예제를 통해 앤트로픽 클로드 3의 유용한 기능을 경험해 볼 수 있었습니다. 앤트로픽의 지속적인 발전과 함께 더 많은 흥미로운 응용 사례들이 나타날 것으로 예상됩니다. 클로드 3과 같은 최신 언어 모델들이 우리의 미래를 어떻게 혁신하고 변화시킬지 기대해 보면서 오늘 블로그 내용은 이상으로 마치도록 하겠습니다.
저는 그럼 다음 시간에 더 유익한 정보로 다시 찾아뵙겠습니다. 감사합니다.

2024.03.07 - [대규모 언어모델] - 클로드(Claude) Sonnet을 이용한 고객리뷰 분류 및 요약 자동화
클로드(Claude) Sonnet을 이용한 고객리뷰 분류 및 요약 자동화
안녕하세요! 오늘은 최근 공개된 클로드 Sonnet 모델을 이용해서 고객의 리뷰를 자동으로 분류하고 요약해 보겠습니다. 수많은 고객의 리뷰를 모두 읽어보고 요약해서 인사이트를 얻으려면 많은
fornewchallenge.tistory.com
'AI 언어 모델' 카테고리의 다른 글
| Dolphin 2.8: 무엇이든 대답하는 무검열 Mistral 최신 모델과 오프라인 대화(크롬 브라우저 Ollama UI) (1) | 2024.04.10 |
|---|---|
| 클로드(Claude) 3 Opus로 arxiv 논문을 초등학생 수준으로 요약하기 (0) | 2024.04.08 |
| 🚀 ReALM, 화면 속 정보를 이해하는 애플의 새로운 AI 기술! (0) | 2024.04.05 |
| 5줄 파이썬 코드로 AI 주식 분석 완료! Hermes 2 Pro의 놀라운 함수 호출 기능 (0) | 2024.03.19 |
| 클로드(Claude) Sonnet을 이용한 고객리뷰 분류 및 요약 자동화 (1) | 2024.03.07 |



