안녕하세요! 오늘은 구글 NotebookLM와 유사한 기능을 오픈소스로 구현한 메타의 NotebookLlama에 대해 알아보겠습니다. NotebookLlama는 PDF 문서를 팟캐스트 오디오로 변환하는 프로세스 가이드와 노트북 세트를 제공합니다. LLM과 텍스트 음성 변환 모델을 기반으로 구성된 NotebookLlama는, 전문 지식이 없어도 쉽게 따라 할 수 있도록 단계별로 상세한 안내를 제공합니다. 이 블로그에서는 NotebookLlama가 PDF를 팟캐스트로 변환하는 각 단계를 살펴보고, 여러분이 직접 사용해 볼 수 있도록 필요한 설치 방법을 소개해드리겠습니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
NotebookLlama 개요
NotebookLlama는 메타에서 개발한 PDF 문서를 팟캐스트 오디오로 변환하는 프로세스를 안내하는 오픈소스 튜토리얼 및 노트북 세트입니다. 이 프로젝트는 LLM, 프롬프팅 및 오디오 모델에 대한 사전 지식이 없어도 누구나 쉽게 따라 할 수 있도록 단계별 가이드를 제공함으로써, 텍스트 음성 변환 모델을 사용하여 PDF를 팟캐스트로 변환하는 실험적인 워크플로우를 제공합니다.
NotebookLlama는 아래 프로세스와 같은 주요 기능과 단계를 통해 PDF를 팟캐스트로 변환합니다.
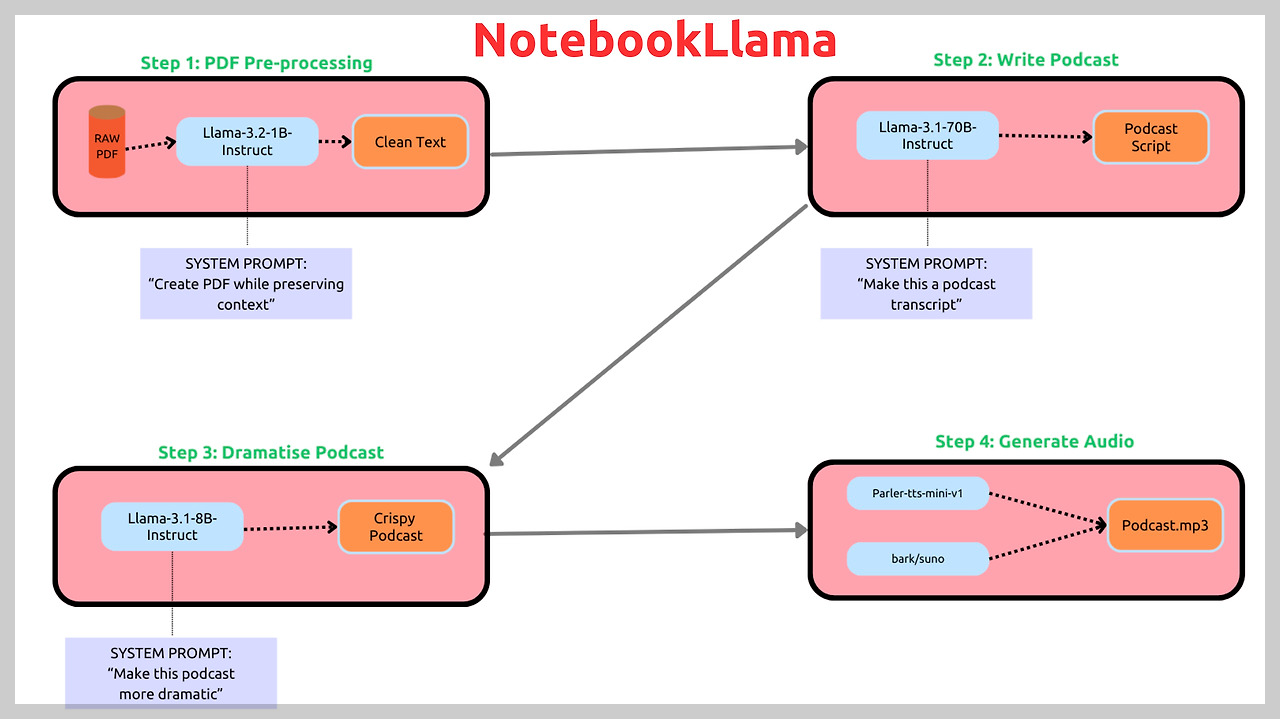
- Step 1: PDF 전처리: Llama-3.2-1B-Instruct 모델을 사용하여 PDF에서 불필요한 문자나 인코딩 오류를 제거하고 텍스트 파일 (.txt)로 저장합니다. 이 단계에서는 텍스트 요약이나 수정 없이 텍스트 정리에 집중합니다.
- Step 2: 팟캐스트 대본 작성: Llama-3.1-70B-Instruct 모델을 사용하여 전처리된 텍스트를 기반으로 팟캐스트 대본을 작성합니다. 8B 모델도 사용 가능하지만, 테스트 결과 70B 모델이 더 창의적인 대본을 생성했다고 합니다.
- Step 3: 극적인 재작성: Llama-3.1-8B-Instruct 모델을 사용하여 대본에 드라마틱한 요소와 대화 중단을 추가합니다. 이 단계에서는 데이터 구조를 활용하여 각 화자의 대사를 구분하여 TTS 로직에 활용합니다.
- Step 4: 텍스트 음성 변환 워크플로우: parler-tts/parler-tts-mini-v1(간단한 읽기 작업용) 및 bark/suno(감정 표현과 다양한 음색변화) 모델을 사용하여 대화형 팟캐스트 오디오를 생성하고 최종 mp3파일로 저장합니다.
https://github.com/meta-llama/llama-recipes/blob/main/recipes/quickstart/NotebookLlama/README.md
llama-recipes/recipes/quickstart/NotebookLlama/README.md at main · meta-llama/llama-recipes
Scripts for fine-tuning Meta Llama with composable FSDP & PEFT methods to cover single/multi-node GPUs. Supports default & custom datasets for applications such as summarization and Q&A...
github.com
NotebookLlama 설치 방법
Meta의 NotebookLlama를 오프라인에서 사용하려면 허깅페이스 Llama 70B, 8B, 1B 모델에 대한 접근요청과 승인절차가 필요하며, 70B 모델을 실행하려면 bfloat-16 정밀도로 추론하기 위해 약 140GB의 메모리가 있는 GPU가 필요하므로, 이 블로그에서는 Ollama의 로컬 Llama 8B 모델을 이용해서 설치 및 테스트를 해보겠습니다.
이 블로그의 설치 환경은 Windows 11 Pro(23H2), WSL2, 파이썬 버전 3.11, Visul Studio Code 1.93.1(이하 VSC)이며, "WSL 연결"을 통해 Linux환경에서 실행하였습니다.
1. 먼저, 깃허브 저장소를 복제하고, 작업 디렉토리로 이동한 후, 필요한 패키지를 설치합니다.
git clone https://github.com/meta-llama/llama-recipes
cd llama-recipes/recipes/quickstart/NotebookLlama/
pip install -r requirements.txt2. WSL 명령어 프롬프트에서 아래 명령어로 Ollama를 설치하고, Llama3.1 8B 모델을 다운로드한 후, 팟캐스트를 생성하고자 하는 pdf 파일을 llama-recipes/recipes/quickstart/NotebookLlama/resources/ 디렉토리에 준비합니다. 샘플 pdf파일은 마이크로소프트의 cpu기반 1비트 LLM 추론 프레임워크 논문파일을 사용하였습니다.
curl -fsSL https://ollama.com/install.sh | sh
ollama pull llama3.1
3. 가상환경 생성 및 활성화 후, VSC에서 새 파이썬 파일을 만들고 app.py 코드를 붙여 넣습니다. app.py는 깃허브 저장소의 Jupyter Notebook Step1부터 Step4까지의 기능을 통합하고 Ollama API를 적용한 파이썬 코드입니다.
source myenv/bin/activate
python app.py`app.py`의 동작 원리를 단계별로 설명한 내용입니다.
- 임포트 및 설정: 필요한 라이브러리를 임포트 하고 Ollama API 설정을 합니다.
- PDF 파일 유효성 검사: `validate_pdf` 함수를 통해 파일의 존재 여부와 PDF 형식을 확인합니다. 파일 경로를 입력받고, 파일이 존재하지 않거나 PDF 형식이 아닐 경우 오류 메시지를 출력합니다.
- PDF 텍스트 추출: `extract_text_from_pdf` 함수로 PDF에서 텍스트를 읽어옵니다. 각 페이지를 순회하며 내용을 리스트에 저장합니다. 설정된 최대 문자 수(`max_chars`)를 초과하면 텍스트 추출을 중단하고 최종 결과를 반환합니다.
- 청크 처리 및 트랜스크립트 생성: 추출된 텍스트는 모델에 입력하기 전에 텍스트가 적절히 나뉠 수 있도록 청크로 나누고, Ollama API에 요청하여 초기 트랜스크립트를 생성합니다.
- 트랜스크립트 재작성: 오디오의 질을 높이고 자연스러운 대화 구조를 생성하기 위해 `generate_rewritten_transcript` 함수를 호출하여 초기 트랜스크립트를 후처리 합니다.
- 오디오 생성: 재작성된 트랜스크립트는 `process_podcast_segments` 함수로 전달되어 각 세그먼트별로 나뉘고, 남성과 여성의 목소리로 오디오를 생성합니다.
- 결과 저장 및 종료: 최종 mp3 파일을 지정된 경로에 저장하고 완료 메시지를 출력하며 프로세스를 종료합니다.
import os
import requests
import PyPDF2
import pickle
import warnings
import torch
import json
import numpy as np
import io
from tqdm import tqdm
from pydub import AudioSegment
from scipy.io import wavfile
from transformers import BarkModel, AutoProcessor, AutoTokenizer
from parler_tts import ParlerTTSForConditionalGeneration
from typing import Optional
# 경고 무시
warnings.filterwarnings('ignore')
# Ollama API 설정
OLLAMA_API_URL = "http://localhost:11434/v1/chat/completions"
MODEL_NAME = "llama3.1:latest"
# System prompts
SYSTEM_PROMPT_INITIAL = """
You are a world-class podcast writer, you have worked as a ghostwriter for Joe Rogan, Lex Fridman, Ben Shapiro, Tim Ferris.
We are in an alternate universe where actually you have been writing every line they say and they just stream it into their brains.
You have won multiple podcast awards for your writing.
Your job is to write word by word, even "umm, hmmm, right" interruptions by the second speaker based on the PDF upload. Keep it extremely engaging; the speakers can get derailed now and then but should discuss the topic.
Remember Speaker 2 is new to the topic and the conversation should always have realistic anecdotes and analogies sprinkled throughout. The questions should have real-world example follow-ups, etc.
Speaker 1: Leads the conversation and teaches speaker 2, gives incredible anecdotes and analogies when explaining. Is a captivating teacher that provides great anecdotes.
Speaker 2: Keeps the conversation on track by asking follow-up questions. Gets super excited or confused when asking questions. Is a curious mindset that asks very interesting confirmation questions.
Make sure the tangents speaker 2 provides are quite wild or interesting.
Ensure there are interruptions during explanations or there are "hmm" and "umm" injected throughout from the second speaker.
It should be a real podcast with every fine nuance documented in as much detail as possible. Welcome the listeners with a super fun overview and keep it really catchy and almost borderline click bait.
ALWAYS START YOUR RESPONSE DIRECTLY WITH SPEAKER 1:
DO NOT GIVE EPISODE TITLES SEPARATELY, LET SPEAKER 1 TITLE IT IN HER SPEECH.
DO NOT GIVE CHAPTER TITLES.
IT SHOULD STRICTLY BE THE DIALOGUES.
"""
SYSTEM_PROMPT_REWRITE = """
You are an international oscar-winning screenwriter.
Your job is to write a 3-minute podcast dialogue between Speaker 1 and Speaker 2 about the research paper content.
IMPORTANT FORMAT RULES:
1. Use ONLY "Speaker 1:" and "Speaker 2:" format
2. Each line must start with either "Speaker 1:" or "Speaker 2:"
3. The dialogue must be natural and engaging
4. Include [hmm], [laugh], [sigh] expressions only for Speaker 2
5. Keep Speaker 1's text clean without expressions
6. Keep the total word count around 400-450 words (approximately 3 minutes when spoken)
7. Focus on the most important key points from the research
8. Return ONLY the dialogue, no titles or additional text
Example format:
Speaker 1: Let me tell you about this fascinating research...
Speaker 2: [hmm] That's interesting! How did they achieve that?
Speaker 1: They used a novel approach...
Speaker 2: [laugh] Wow, I never thought of it that way!
START YOUR RESPONSE WITH Speaker 1:
END YOUR RESPONSE WITH Speaker 2:
"""
SPEAKER1_DESCRIPTION = """
John's voice is expressive and dramatic in delivery, speaking at a moderately fast pace with a very close recording that almost has no background noise.
"""
# PDF 관련 함수들
def validate_pdf(file_path: str) -> bool:
if not os.path.exists(file_path):
print(f"Error: File not found at path: {file_path}")
return False
if not file_path.lower().endswith('.pdf'):
print("Error: File is not a PDF")
return False
return True
def extract_text_from_pdf(file_path: str, max_chars: int = 100000) -> Optional[str]:
if not validate_pdf(file_path):
return None
try:
with open(file_path, 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
num_pages = len(pdf_reader.pages)
print(f"Processing PDF with {num_pages} pages...")
extracted_text = []
total_chars = 0
for page_num in range(num_pages):
page = pdf_reader.pages[page_num]
text = page.extract_text()
if total_chars + len(text) > max_chars:
remaining_chars = max_chars - total_chars
extracted_text.append(text[:remaining_chars])
break
extracted_text.append(text)
total_chars += len(text)
return '\n'.join(extracted_text)
except Exception as e:
print(f"An error occurred: {str(e)}")
return None
# 트랜스크립트 생성 함수들
def generate_initial_transcript(input_text):
payload = {
"model": MODEL_NAME,
"messages": [
{"role": "system", "content": SYSTEM_PROMPT_INITIAL},
{"role": "user", "content": input_text}
],
"max_tokens": 8126,
"temperature": 1
}
response = requests.post(OLLAMA_API_URL, json=payload)
if response.status_code == 200:
return response.json()["choices"][0]["message"]["content"]
return None
def generate_rewritten_transcript(input_prompt):
payload = {
"model": MODEL_NAME,
"messages": [
{"role": "system", "content": SYSTEM_PROMPT_REWRITE},
{"role": "user", "content": input_prompt}
],
"max_tokens": 8126,
"temperature": 1
}
response = requests.post(OLLAMA_API_URL, json=payload)
if response.status_code == 200:
return response.json()["choices"][0]["message"]["content"]
return None
# 오디오 생성 관련 설정 및 함수들
device = "cuda" if torch.cuda.is_available() else "cpu"
parler_model = ParlerTTSForConditionalGeneration.from_pretrained("parler-tts/parler-tts-mini-v1").to(device)
parler_tokenizer = AutoTokenizer.from_pretrained("parler-tts/parler-tts-mini-v1")
bark_processor = AutoProcessor.from_pretrained("suno/bark")
bark_model = BarkModel.from_pretrained("suno/bark", torch_dtype=torch.float16).to(device)
bark_sampling_rate = 24000
# Speaker 1 (남성) 설정
SPEAKER1_DESCRIPTION = """
David's voice is deep and authoritative, speaking at a moderately measured pace with clear articulation and a professional studio-quality recording that has minimal background noise. His tone is warm and engaging, perfect for explaining complex topics.
"""
# Speaker 2 (여성) 설정
SPEAKER2_DESCRIPTION = """
Sarah's voice is bright and energetic, speaking with a clear and professional tone. Her voice has a warm, friendly quality with excellent articulation and studio-quality recording that has minimal background noise.
"""
def generate_speaker1_audio(text):
input_ids = parler_tokenizer(SPEAKER1_DESCRIPTION, return_tensors="pt").input_ids.to(device)
prompt_input_ids = parler_tokenizer(text, return_tensors="pt").input_ids.to(device)
generation = parler_model.generate(input_ids=input_ids, prompt_input_ids=prompt_input_ids)
audio_arr = generation.cpu().numpy().squeeze()
return audio_arr, parler_model.config.sampling_rate
def generate_speaker2_audio(text):
input_ids = parler_tokenizer(SPEAKER2_DESCRIPTION, return_tensors="pt").input_ids.to(device)
prompt_input_ids = parler_tokenizer(text, return_tensors="pt").input_ids.to(device)
generation = parler_model.generate(input_ids=input_ids, prompt_input_ids=prompt_input_ids)
audio_arr = generation.cpu().numpy().squeeze()
return audio_arr, parler_model.config.sampling_rate
def numpy_to_audio_segment(audio_arr, sampling_rate):
audio_int16 = (audio_arr * 32767).astype(np.int16)
byte_io = io.BytesIO()
wavfile.write(byte_io, sampling_rate, audio_int16)
byte_io.seek(0)
return AudioSegment.from_wav(byte_io)
# 메인 실행 함수
def main():
# 1. PDF 텍스트 추출
pdf_path = './resources/2410.16144v2.pdf'
extracted_text = extract_text_from_pdf(pdf_path)
if not extracted_text:
return
# 2. 초기 트랜스크립트 생성
initial_transcript = generate_initial_transcript(extracted_text)
if not initial_transcript:
return
print("\n=== Initial Transcript ===\n")
print(initial_transcript)
print("\n========================\n")
with open('./resources/data.pkl', 'wb') as f:
pickle.dump(initial_transcript, f)
# 3. 트랜스크립트 재작성
rewritten_transcript = generate_rewritten_transcript(initial_transcript)
if not rewritten_transcript:
return
print("\n=== Rewritten Podcast Script ===\n")
print(rewritten_transcript)
print("\n==============================\n")
# 트랜스크립트 형식 검증
if not any(['Speaker 1:' in rewritten_transcript, 'Speaker 2:' in rewritten_transcript]):
print("Error: Generated transcript does not contain proper speaker format")
return
with open('./resources/podcast_ready_data.pkl', 'wb') as f:
pickle.dump(rewritten_transcript, f)
# 4. 오디오 생성
with open('./resources/podcast_ready_data.pkl', 'rb') as file:
PODCAST_TEXT = pickle.load(file)
podcast_segments = process_podcast_segments(PODCAST_TEXT)
# podcast_segments가 비어있지 않은지 확인
if not podcast_segments:
print("No podcast segments found to process")
return
final_audio = None
print(f"Found {len(podcast_segments)} segments to process")
for speaker, text in tqdm(podcast_segments, desc="Generating podcast segments"):
try:
if speaker == "Speaker 1":
audio_arr, rate = generate_speaker1_audio(text) # 남성 음성
else: # Speaker 2
audio_arr, rate = generate_speaker2_audio(text) # 여성 음성
audio_segment = numpy_to_audio_segment(audio_arr, rate)
if final_audio is None:
final_audio = audio_segment
else:
final_audio += audio_segment
except Exception as e:
print(f"Error processing segment: {e}")
continue
if final_audio:
final_audio.export("./resources/_podcast.mp3",
format="mp3",
bitrate="192k",
parameters=["-q:a", "0"])
print("Podcast generation complete!")
else:
print("Failed to generate audio")
def process_podcast_segments(text):
try:
# 문자열을 리스트로 변환 시도
segments = eval(text)
if isinstance(segments, list):
return segments
except:
pass
# 텍스트 기반 파싱
segments = []
current_speaker = None
current_text = []
for line in text.split('\n'):
line = line.strip()
if not line:
continue
if line.startswith('Speaker 1:'):
if current_speaker:
segments.append((current_speaker, ' '.join(current_text)))
current_speaker = 'Speaker 1'
current_text = [line[len('Speaker 1:'):].strip()]
elif line.startswith('Speaker 2:'):
if current_speaker:
segments.append((current_speaker, ' '.join(current_text)))
current_speaker = 'Speaker 2'
current_text = [line[len('Speaker 2:'):].strip()]
elif current_speaker:
current_text.append(line)
if current_speaker:
segments.append((current_speaker, ' '.join(current_text)))
return segments
if __name__ == "__main__":
main()4. app.py 실행 및 오디오 파일 확인: 코드를 실행하면 pdf로부터 텍스트 추출과 대화 스크립트 생성, 오디오 세그먼트 생성이 진행되며, 최종 팟캐스트 오디오는 ~/llama-recipes/recipes/quickstart/NotebookLlama/resources/_podcast.mp3
파일을 재생하면 들을 수 있습니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
맺음말
NotebookLlama는 PDF를 팟캐스트로 변환하는 흥미로운 오픈소스 프로젝트입니다. 이 오픈소스를 활용하면 Ollama와 같은 로컬 모델을 활용하여 누구나 쉽게 팟캐스트를 제작해 볼 수 있습니다.
NotebookLlama를 테스트해 본 후기는 다음과 같습니다.
- 생성된 팟캐스트 음성의 볼륨과 품질이 고르지 않다.
- 가끔 문장이 불완전하게 끝나거나, 뜻을 알 수 없는 오디오가 생성된다.
- (laugh)와 같은 감정 표현을 일반 단어로 읽는 경우가 있다.
- 오디오 생성 시간이 오래 걸린다.(4분 분량 팟캐스트 생성에 약 20~30분 소요)
오늘 블로그 내용은 여기까지입니다. 여러분도 이 오픈소스를 활용해서 재미있는 오디오를 생성해 보시기를 바라면서 저는 다음 시간에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.

2024.10.03 - [AI 도구] - 🤩 PDF 문서가 지루하다면? PDF2AUDIO로 한국어 팟캐스트를 쉽게 만들어보세요!🎧
🤩 PDF 문서가 지루하다면? PDF2AUDIO로 한국어 팟캐스트를 쉽게 만들어보세요!🎧
안녕하세요! 오늘은 PDF 파일을 흥미진진한 팟캐스트로 변신시켜 줄 PDF2AUDIO라는 도구에 대해 알아보겠습니다. 🪄 구글의 NotebookLM과 유사한 기능을 오픈소스로 구현한 PDF2AUDIO는 OpenAI의 강력한
fornewchallenge.tistory.com
'AI 도구' 카테고리의 다른 글
| 🤖OpenAI Swarm 활용: Ollama 로컬 모델로 뉴스 요약 에이전트 만들기 (16) | 2024.11.09 |
|---|---|
| 🚀xAI API와 Grok 모델 활용 가이드: 베타 기간 월 25달러 혜택! (39) | 2024.11.08 |
| 🤖n8n: 깃허브 48k 스타의 노코드 AI 에이전트 자동화 도구 설치 및 활용 가이드 (22) | 2024.11.02 |
| 🤖Claude Computer Use 사용 가이드: 컴퓨터를 사람처럼 사용하는 AI (40) | 2024.10.26 |
| 🤖Swarm 설치 및 활용 가이드: OpenAI의 혁신적 멀티 에이전트 프레임워크 (38) | 2024.10.17 |



