목차
안녕하세요! 최근 언어 모델이 자연어 처리 연구와 상업 제품에서 더욱 보편화되면서, 모델의 편향과 잠재적인 위험을 이해하기 위한 훈련 데이터와 아키텍처 및 개발에 대한 세부 정보가 중요해지고 있는데요. 오늘은 앨런 AI연구소에서 최근에 발표된 완전한 오픈소스 대형 언어 모델, OLMo(Open Language Model)에 대해서 알아보겠습니다. OLMo는 진정한 개방형 언어 모델로, 모델 가중치와 추론 코드, 훈련 데이터, 평가 코드 등 모든 프레임워크를 공개합니다. 이 블로그에서는 OLMo의 아키텍처, 특징, 평가결과 등에 대해서 확인하실 수 있습니다.

https://www.aitimes.com/news/articleView.html?idxno=156940
AI2, 상업 활용까지 자유로운 '진짜' 오픈 소스 LLM '올모' 출시 - AI타임스
앨런AI연구소(AI2)가 완전한 오픈 소스 대형언어모델(LLM) \'올모(OLMo)’를 출시했다. 데이터 수집, 학습, 배포의 전 과정을 투명하게 공개한 데다 상업적 사용까지 허용한 진정한 의미의 오픈 소스
www.aitimes.com
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
논문 개요 및 목적
- 논문제목 : OLMo: Accelerating the Science of Language Models
- 논문저자 : Allen Institute for Artificial Intelligence
- 논문게재 사이트 https://arxiv.org/abs/2402.00838
- 논문게재일 : 2024.2

이 논문의 목적은 언어 모델에 대한 연구 및 이해를 촉진하고, 특히 언어 모델의 세부 사항 및 훈련 데이터에 대한 공개적인 접근을 위해 OLMo라는 완전한 오픈 언어 모델과 이를 구축하고 연구하기 위한 프레임워크를 제시합니다. 이 프레임워크는 훈련 데이터, 훈련 및 평가 코드, 중간 모델 체크포인트, 그리고 훈련 로그를 포함하여 전체적인 모델에 대한 열람 권한을 공개합니다.
또한, 이 보고서는 다양한 규모와 변형의 모델, 훈련 및 평가 도구, 그리고 연구에 필요한 데이터셋 및 분석 도구를 공개하고 있습니다. 이러한 노력을 통해 저자들은 언어 모델의 다양한 측면에 대한 과학적 연구를 촉진하고, 연구 커뮤니티에 열린 모델에 대한 자원을 제공하여 혁신과 발전에 기여합니다.
논문의 연구내용 및 결과
OLMo(Open Language Model)의 프레임워크는 모델 및 아키텍처, 사전 훈련 데이터 Dolma, 평가 프레임워크 세 가지 주요 구성 요소로 이루어져 있습니다.
1. OLMo 모델의 아키텍처
OLMo 모델은 디코더 전용 트랜스포머 아키텍처를 채택하고 있습니다. 특정한 아키텍처는 트랜스포머 아키텍처의 초기버전인 바닐라 트랜스포머*에 대한 개선 사항을 포함하고 있으며, PaLM, LLaMA, OpenLM, Falcon 등과 같은 최근 대형 언어 모델을 참고하여 개발되었습니다. OLMo 모델은 1B 및 7B 버전을 제공하며, 향후 65B 버전이 출시될 예정입니다. 아키텍처 크기, 레이어 수, 히든 크기, 어텐션 헤드 수 및 훈련된 토큰 수와 같은 다양한 사양은 아래 표에서 확인할 수 있습니다. 바닐라 트랜스포머에 대한 내용은 아래 더 보기를 클릭하시면 확인하실 수 있습니다,
*바닐라 트랜스포머(Vanilla Transformer)"는 Vaswani et al. (2017)의 논문에서 소개된 트랜스포머 모델의 초기 버전을 지칭합니다. 이 모델은 "Attention is All You Need"라는 논문에서 제안되었으며, 자연어 처리 및 기계 번역 작업에 적용할 수 있는 새로운 신경망 아키텍처를 제시했습니다. 바닐라 트랜스포머는 기존의 순환 신경망(RNN)이나 장단기 메모리(LSTM)와 같은 시퀀스 모델 대신, 어텐션 메커니즘을 중심으로 하는 셀프 어텐션 메커니즘을 사용하여 시퀀스 데이터를 처리합니다. 이로써 트랜스포머는 긴 범위의 문맥을 효과적으로 학습할 수 있게 되었고, 병렬 계산이 가능한 구조로 인해 훈련 속도가 향상되었습니다. 바닐라 트랜스포머의 주요 특징은 다음과 같습니다:
- 셀프 어텐션 메커니즘(Self-Attention Mechanism):문장의 각 단어가 다른 단어들과 어떤 관계를 맺고 있는지를 계산할 수 있는 어텐션 메커니즘을 도입했습니다.
- 멀티헤드 어텐션(Multi-Head Attention): 어텐션을 여러 가지 다른 가중치 행렬로 계산하여 다양한 정보를 학습할 수 있도록 했습니다.
- 포지셔널 인코딩(Positional Encoding): 단어의 위치 정보를 모델에 전달하기 위해 포지셔널 인코딩을 도입했습니다.
- 피드포워드 신경망(Feedforward Neural Network): 각 어텐션 블록 이후에 적용되는 피드포워드 신경망을 통해 비선형성을 도입했습니다.
바닐라 트랜스포머는 이후에 다양한 자연어 처리 작업 및 기계 번역에서 기본 모델로 채택되고, 다양한 변형 및 발전된 모델들이 이어져 나왔습니다.

바닐라 트랜스포머 대비 OLMo 모델 아키텍처의 주요 특징은 다음과 같습니다:
- 편향 제외: LLaMA, PaLM 등과 같이 모든 편향 용어를 제외하여 훈련 안정성을 향상시킵니다.
- 비매개변수 계층 정규화: 매개변수를 사용하지 않고 정규화를 사용하는 안전한 옵션으로 빠른 속도를 제공합니다.
- SwiGLU 활성화 함수: 간단한 비선형 활성화 함수인 ReLU 대신 ReLU와 시그모이드 활성화 함수를 결합하여, 입력신호의 가중치 합의 결과를 다음 층의 출력으로 변환하며, 모델의 크기를 조절하여 처리량을 향상시킵니다.
- 회전 위치 임베딩: 절대 위치 임베딩 대신 특정 위치에 대한 임베딩을 회전시켜 새로운 표현을 생성하는 방식으로, 긴 시퀀스에 대한 모델의 처리 능력을 향상시키고, 효과적으로 시퀀스의 위치 정보를 모델에 전달합니다.
- 어휘: 텍스트를 쌍(pair) 단위로 분할하고, 가장 빈번하게 등장하는 쌍을 합쳐서 새로운 토큰을 생성하는 BPE(Byte Pair Encoding) 기반의 토크나이저를 적용하고, 개인 식별정보 마스킹을 위한 추가 토큰을 포함하며, 최종으로 학습한 어휘 크기는 50,280입니다.
2. 사전 훈련 데이터: Dolma
Dolma는 OLMo 모델의 사전 훈련을 위한 데이터셋으로, 7개 다양한 소스에서 얻은 3조 토큰의 다양한 코퍼스(말뭉치)로 구성되어 있습니다. 이 데이터는 언어 필터링, 품질 필터링, 콘텐츠 필터링, 중복 제거, 다중 소스 혼합 및 토큰화를 통해 구축되었습니다. 아래 표는 각 소스의 데이터 양에 대한 개요를 제공합니다.
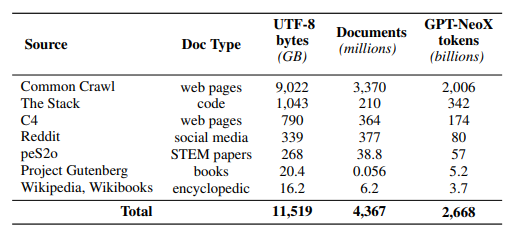
Dolma 데이터 셋 언어 모델을 사전 훈련하기 위한 목적으로 사용되며, 이를 통해 모델이 자연어를 이해하고 생성하는 데 필요한 정보를 효과적으로 학습합니다. Dolma 데이터 셋의 주요 특징과 구성 요소는 다음과 같습니다:
- 다양한 출처: Dolma는 여러 출처에서 수집된 코퍼스로 구성되어 있습니다. 이 데이터는 대규모로 수집되었으며, 웹 페이지, 코드, 소셜 미디어, 학문적 논문, 프로젝트 구텐베르크 등 다양한 소스에서 가져온 텍스트를 포함합니다.
- 언어적 다양성: Dolma는 다양한 언어적 특성을 반영하도록 구성되어 있습니다. 이는 여러 언어, 어휘, 문체, 주제, 어휘의 다양한 사용 등을 포함하여 언어적 다양성을 고려한 것입니다.
- 전처리 및 정제: Dolma는 다양한 전처리 및 정제 단계를 거쳐 구축되었습니다. 이는 언어 모델의 품질 향상과 모델이 다양한 언어적 특성을 학습할 수 있도록 도움을 줍니다.
- Dolma 툴킷: Dolma 데이터 세트의 구축에 사용된 도구 및 프로세스에 대한 정보를 담은 Dolma 툴킷이 제공됩니다. 이는 데이터의 구성, 전처리, 정제, 및 기타 중요한 세부 사항에 대한 문서화를 포함합니다.
Dolma는 OLMo 프로젝트에서 제공하는 오픈 소스 데이터로, 이를 사용하여 언어 모델의 사전 훈련을 수행하고, 모델의 성능 및 능력을 평가할 수 있습니다. 데이터의 투명성과 문서화는 모델의 훈련 및 평가에 대한 신뢰성과 효과성을 증진시키는 데 기여합니다.
3. 평가 프레임워크 및 결과
평가는 온라인 평가와 오프라인 평가 두 단계에서 이루어집니다. 온라인 평가는 1000 훈련 단계마다 실행되며, 모델 품질에 대한 초기 및 지속적인 신호를 제공합니다. 오프라인 평가도구는 Catwalk 프레임워크 및 Paloma 등을 활용하여 수행되며, 다운스트림 및 내재적 언어 모델링 평가를 포함합니다.
- 온라인 평가 (Online Evaluation): 이 부분에서는 모델의 훈련 도중에 온라인으로 평가를 수행하는 방법에 대해 다룹니다. 훈련 중에 모델의 성능을 지속적으로 모니터링하고 평가하여 어떠한 변화나 개선이 있는지 확인합니다. 평가는 약 1000번의 훈련 단계(또는 약 4조 훈련 토큰)마다 실행되며, 이를 통해 모델의 품질에 대한 초기 및 지속적인 피드백을 얻을 수 있습니다.
- 오프라인 평가 (Offline Evaluation): 다양한 데이터셋과 작업 형식에 대한 평가를 수행합니다. 일련의 핵심 작업들에 대한 제로샷(Zero-shot) 성능을 평가하는 다운스트림 평가와 훈련 데이터의 언어 분포를 얼마나 잘 모방하는지 평가하는 내재적 언어 모델링 평가를 포함합니다. 다운스트림 평가는 모델이 실제 응용 프로그램에서 얼마나 잘 수행되는지를 측정하는 것이며, 내재적 언어 모델링 평가는 모델이 언어를 얼마나 잘 이해하고 생성하는지를 측정합니다.
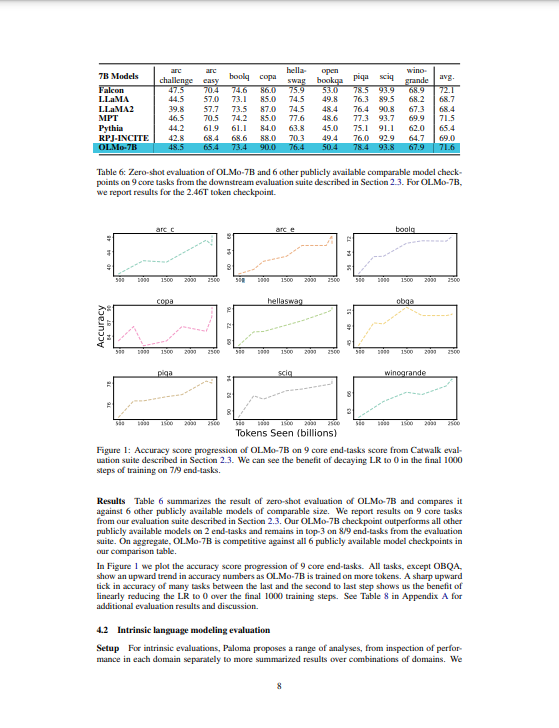
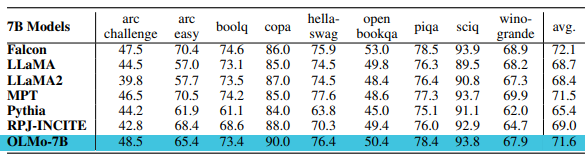
OLMo-7B 모델의 오프라인 평가 결과는 다음과 같이 요약됩니다. 온라인 평가 결과는 논문에서 구체적으로 언급되지 않았습니다.
- 다운스트림 평가: OLMo-7B는 Catwalk 프레임워크를 사용하여 오프라인 평가되었습니다. 9개 핵심 태스크에서 zero-shot 평가를 수행하였고, 2.46T 토큰의 체크포인트를 사용하였습니다. OLMo-7B는 9개의 핵심 태스크 중 2개에서 다른 비슷한 규모의 모델들을 능가하였으며, 8개 태스크에서는 최상위 3개 중에 속했습니다.
- 내재적 언어 모델링 평가: 다양한 데이터 소스에 대한 언어 모델의 내재적 성능을 평가하였습니다. OLMo-7B는 11가지 데이터 소스를 기반으로 한 평가에서 다른 모델들과 유사한 성능을 보여주었습니다. 성능은 데이터 분포의 유사성에 따라 다르며, 웹 크롤링 데이터 셋인 C4(Common Crawl)과 관련된 평가에서 강점을 보였습니다. 다음 그래프는 모델이 어떤 데이터에 대해 얼마나 효율적으로 학습되었는지를 측정하는 Bits per byte지표 평가결과입니다.

이러한 결과들은 OLMo-7B가 다양한 평가 방법 및 작업에서 경쟁력 있는 성능을 보인다는 것을 시사합니다.

논문의 결론 및 전망
이 논문은 OLMo의 첫 번째 릴리스를 소개하며 언어 모델링을 구축하고 연구하기 위한 전체 프레임워크를 제공합니다. 이전 노력들이 모델 가중치와 추론 코드만을 공개한 반면, 논문은 OLMo와 함께 훈련 데이터 및 훈련 및 평가 코드를 비롯한 전체 프레임워크를 공개합니다. 연구팀은 훈련 로그, 제거 실험 결과, 연구 발견, 그리고 머신러닝 실험 추적 시각화 플랫폼 Weights & Biases의 로그도 곧 공개할 예정입니다.
연구팀은 OLMo를 명령어 조정 및 RLHF(Reinforcement Learning with Human Feedback, 인간 피드백 활용 강화 학습) 등 다양한 형태로 적응시키는 연구를 진행 중이며 이에 따른 적응된 모델들과 적응 모델 코드 및 데이터도 공개할 예정입니다. 또한 연구팀은 OLMo 및 그 프레임워크를 지속적으로 지원하고, 개방적인 연구 커뮤니티를 강화하기 위해 오픈 언어 모델의 경계를 계속해서 넓혀나갈 예정으로, 이를 위해 다양한 모델 크기, 모달리티, 데이터셋, 안전 조치 및 평가 방법을 OLMo 패밀리로 도입할 계획입니다.
오늘은 앨런 AI 연구소에서 선보인 최신 언어 모델, OLMo(Open Language Model)에 대해 알아보았습니다. OLMo는 완전한 오픈 소스 대형 언어 모델로, 모델 가중치와 추론 코드뿐만 아니라 훈련 데이터, 평가 코드, 전체 프레임워크를 투명하게 공개합니다. 이와 같은 연구 노력을 통해 오픈 연구 커뮤니티를 더욱 강화하고 새로운 혁신의 물결이 일어날 것을 기대해 보면서 저는 다음에 더욱 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.
2024.02.02 - [AI 논문 분석] - [AI 논문] InstantID: 얼굴 사진 한장으로 딥페이크 생성
[AI 논문] InstantID: 얼굴 사진 한장으로 딥페이크 생성
안녕하세요! 오늘은 베이징의 스타트업 인스턴트 X가 개발한 얼굴 사진 한 장으로 원본에 충실한 딥페이크를 생성하는 InstantID라는 기술에 대해서 알아보겠습니다. InstantID의 핵심은 IdentityNet이
fornewchallenge.tistory.com
'AI 논문 분석' 카테고리의 다른 글
| 🚀 SDXL-Lightning: 스테이블 디퓨전 기반 초고속 이미지 생성 기술 심층 분석 (2) | 2024.02.23 |
|---|---|
| 뤼미에르: 구글의 텍스트 기반 비디오 생성의 새로운 기준 (4) | 2024.02.08 |
| [AI 논문] InstantID: 얼굴 사진 한장으로 딥페이크 생성 (0) | 2024.02.02 |
| 코드생성 AI AlphaCodium: 프롬프트 엔지니어링에서 플로우 엔지니어링으로 (0) | 2024.02.01 |
| [AI 논문] 코알라: '달리'보다 5배 빠른 ETRI의 이미지 생성 모델 (2) | 2024.01.30 |




