목차
안녕하세요! 오늘은 틱톡으로 유명한 중국의 IT기업, ByteDance에서 개발한 SDXL-Lightning이라는 이미지 생성모델에 대한 논문을 살펴보겠습니다. SDXL-Lightning은 " 점진적 적대적 확산 증류(Progressive Adversarial Diffusion Distillation)"라는 접근방식을 이용하여 한 단계 또는 몇 단계의 샘플링 만으로 이미지 생성이 가능한 기술입니다. 이 블로그에서는 점진적 적대적 확산 증류의 개념과 동작원리, 오픈소스 SDXL-Lightning 설치방법에 대해 알아보겠습니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
논문 개요
이번 논문의 제목은 "SDXL-Lightning: Progressive Adversarial Diffusion Distillation"입니다. 이 논문은 텍스트를 이미지로 변환하는 과정에서 " 점진적 적대적 확산 증류"라는 새로운 접근 방식을 제시합니다.
- 논문제목: SDXL-Lightning: Progressive Adversarial Diffusion Distillation
- 논문저자: ByteDance Inc.
- 논문게재 사이트: https://arxiv.org/abs/2402.13929
- 논문게재일: 2024.2


이 논문의 목적은 새로운 "점진적 적대적 확산 증류(Progressive Adversarial Diffusion Distillation)"를 사용하여 한 단계 또는 몇 단계의 샘플링만으로 텍스트 대 이미지 생성 모델을 개발하는 것이며, 이 방법을 통해 이전의 모델들보다 더 우수한 이미지 품질을 달성하고, 이를 오픈 소스로 공개하여 생성형 AI에 대한 연구를 진전시키고자 합니다.
논문의 연구내용 및 결과
이 논문에서 제시한 이미지 생성기술은 점진적 적대적 확산 증류(Progressive Adversarial Diffusion Distillation) 방식으로 큰 모델에서 작은 모델로의 지식 전달이 이루어지면서, 작은 모델은 더 많은 단계에서 이미지를 생성하는 능력을 향상시킵니다.
점진적 적대적 확산 증류
"점진적"은 단계적인 진행을 의미하며, 여기서는 학습 프로세스가 단계별로 진행되는 것을 나타냅니다. 초기 단계에서는 크고 복잡한 모델(teacher model, 선생 모델)이 사용되고, 이 모델로부터 더 작고 간단한 모델(student model, 학생 모델)이 점진적으로 생성됩니다.
"적대적"은 경쟁적인 학습 방식을 나타내며, 여기서는 선생 모델과 학생 모델 사이에 경쟁 관계가 있습니다. 학생 모델은 선생 모델의 출력을 흉내내고자 하지만, 선생 모델은 가능한 한 학생 모델의 성능을 저하시키려고 노력합니다. 이러한 상호 작용은 학생 모델이 더 나은 성능을 발휘할 수 있도록 도와줍니다.
"확산 증류"(Diffusion Distillation)는 샘플을 생성하는 과정에서 확산(diffusion)을 통해 점진적으로 정보를 전파하고, 이 정보를 증류(distillation)하여 모델을 학습시키는 방법입니다. 이 방법은 이미지 생성 모델을 학습하는 데 사용되며, 다음과 같은 원리를 따릅니다.
- 확산(Diffusion): 초기에 무작위로 생성된 잡음(noise)을 입력으로 받아서, 점진적으로 실제 이미지로 수렴하도록 합니다. 이 과정에서 생성된 이미지는 노이즈의 영향을 점차적으로 잃어가며 실제 데이터 분포를 따라가게 됩니다.
- 적대적 증류(Adversarial Distillation): 학생 모델(student model)을 선생 모델(teacher model)로부터 학습시키는 과정에서 적대적인 요소가 도입됩니다. 학생 모델이 생성한 샘플과 선생 모델이 생성한 샘플 간의 차이를 최소화하기 위해 적대적 손실 함수가 사용됩니다. 이 과정에서 학생 모델은 점진적으로 선생 모델의 성능을 따라가도록 훈련됩니다.
아래 더보기를 클릭하시면 적대적 손실 함수에 대해서 더 자세히 확인하실 수 있습니다.
적대적 손실 함수(Adversarial Loss Function)는 생성 모델의 학습에서 사용되는 손실 함수 중 하나로, 주로 생성자(generator)와 판별자(discriminator) 간의 경쟁을 조절하는 데 사용됩니다. 이러한 손실 함수는 Generative Adversarial Networks(GANs)에서 널리 사용되며, 생성자는 실제 데이터 분포를 흉내 내는 샘플을 생성하고, 판별자는 생성된 샘플을 실제 데이터와 구별하려고 노력합니다. 가장 일반적인 적대적 손실 함수는 다음과 같이 정의됩니다:
1. 생성자 손실(Genrator Loss): 생성자가 실제 데이터와 구별되지 않도록 생성된 샘플을 실제 데이터로 판별되도록 유도하는 손실입니다. 일반적으로 생성된 샘플을 판별자가 실제 데이터로 잘못 분류했을 때 손실이 최소화됩니다.
2. 판별자 손실(Discriminator Loss): 판별자가 생성된 샘플을 실제 데이터와 올바르게 구별할 수 있도록 유도하는 손실입니다. 즉, 생성된 샘플을 실제 데이터로 판별하고, 실제 데이터를 실제 데이터로 판별하도록 합니다. 일반적으로 적대적 손실 함수는 교대적으로 최적화되며, 생성자와 판별자 간의 균형을 유지하도록 합니다.
이러한 손실 함수는 생성자가 실제 데이터와 유사한 샘플을 생성하도록 유도하고, 판별자는 생성된 샘플을 실제 데이터와 구별하도록 학습시킵니다. 이 과정에서 생성자는 실제 데이터 분포를 학습하고, 판별자는 이를 구별하는 능력을 향상시킵니다.
- 점진적 학습(Progressive Learning): 확산 증류에서는 점진적인 학습이 이루어집니다. 먼저 큰 해상도의 이미지를 생성할 수 있는 모델로부터 학습을 시작하고, 이를 점진적으로 작은 해상도의 이미지를 생성할 수 있는 모델로 변환시킵니다. 이를 통해 학습이 더욱 안정적으로 이루어지며, 높은 해상도의 이미지를 생성할 수 있는 능력이 향상됩니다.
- 반복적인 증류 과정(Iterative Distillation): 확산 증류는 여러 번의 증류 과정을 거치면서 학생 모델을 점진적으로 향상시킵니다. 각 증류 단계에서는 학생 모델이 선생 모델로부터 더 많은 정보를 흡수하고, 더 나은 성능을 발휘할 수 있도록 합니다.
이러한 원리를 통해 확산 증류는 "점진적인 학습"과 "적대적 증류"를 결합하여 이미지 생성 모델을 효과적으로 학습시키는 방법으로 사용됩니다. 점진적 적대적 확산 증류의 동작순서는 다음과 같습니다.
- 1. 초기 단계: 먼저, MSE(Mean Squared Error, 평균 제곱 오차) 손실을 사용하여 큰 모델(128 단계)에서 작은 모델(32 단계)로 직접 증류를 수행합니다. 증류(distillation)는 학습의 한 형태이며, 일반적으로 더 큰 모델(선생 모델)의 지식을 더 작은 모델(학생 모델)로 전달하는 과정입니다. MSE는 예측 값과 실제 값 사이의 차이를 제곱한 후 평균을 계산하는 손실 함수로 모델이 예측한 값과 실제 값 사이의 오차를 측정하고 그 오차를 최소화하도록 모델을 학습시키는 것
- 2. 적대적 손실(Adversarial Loss)을 사용한 점진적 증류: 그다음, 증류 단계를 32 → 8 → 4 → 2 → 1 순서로 점진적으로 모델을 감소시키며 적대적 손실을 사용하여 모델을 증류합니다. 각 단계에서는 먼저 모델이 입력과 출력 간의 연속성을 유지하기 위해 "조건부 목적(conditional objective)"을 사용하여 학습하고, 그런 다음 모델이 더 다양한 데이터를 생성할 수 있도록 "무조건적 목적(unconditional objective)"을 사용하여 학습합니다.
- 3. LoRA를 사용한 증류: 각 단계에서 먼저 LoRA를 사용하여 조건부 목적과 무조건적 목적, 두 가지 목적을 가지고 학습한 다음, LoRA를 병합하고 무조건적 목적을 사용하여 전체 UNet의 파라미터를 최적화합니다.
점진적 적대적 확산 증류의 동작원리를 요약하면, 초기 단계에서는 MSE 손실을 사용하여 큰 모델(선생 모델)에서 작은 모델(학생 모델)로 직접 증류를 수행하고, 그다음, 적대적 손실을 사용하여 점진적으로 모델을 줄여가면서 증류를 수행합니다. 각 단계에서는 조건부 목적과 무조건적 목적을 사용하여 모델을 학습하고, LoRA를 사용하여 증류를 진행한 후 전체 UNet을 추가적으로 학습하여 최적화합니다.
SDXL-Lightning 성능평가
논문에서는 제안된 기술의 성능을 다양한 지표를 사용하여 평가하였습니다. 실험 결과, 제시된 기술이 기존 방법들보다 우수한 성능을 보였으며, 높은 품질의 이미지를 생성할 수 있음이 입증되었습니다. 아래 표를 보시면 SDXL-Lightning은 고품질 샘플을 생성하는 데 필요한 단계 수가 다른 모델에 비해 가장 적습니다.

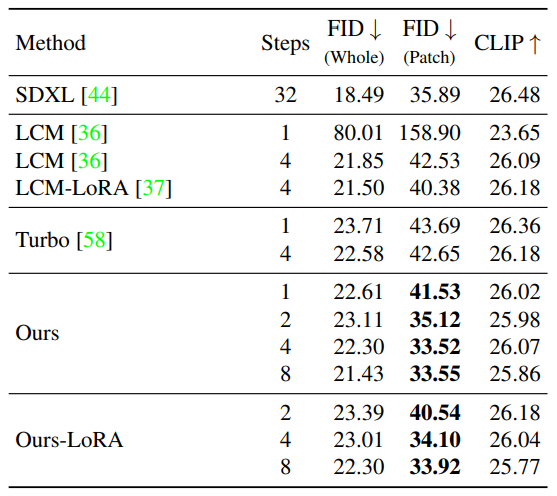
다음 표에서는 SDXL-Lightning 성능 평가 결과를 나타낸 표입니다. 표에서 사용된 지표에 대한 설명은 다음과 같습니다.
- FID-Whole은 Frechet Inception Distance의 전체 이미지에 대한 지표입니다. 이것은 이미지의 전체적인 품질과 다양성을 측정합니다. FID는 두 개의 이미지 집합 간의 차이를 측정하며, FID-Whole은 이 차이를 전체 이미지에 대해 계산한 것입니다. FID-Whole이 낮을수록 생성된 이미지는 실제 이미지와 더 유사하며 더 높은 품질과 다양성을 갖추고 있음을 나타냅니다.
- FID-Patch는 Frechet Inception Distance의 패치 이미지에 대한 지표입니다. 이것은 이미지의 고해상도 세부 정보를 평가하기 위해 이미지의 패치에 대해 FID를 계산합니다. FID-Patch가 낮을수록 생성된 이미지의 고해상도 세부 정보가 실제 이미지와 더 유사하고 더 나은 품질을 갖추고 있음을 나타냅니다.
- CLIP 점수는 모델이 텍스트와 이미지 간의 관계를 얼마나 정확하게 이해하고 측정하는지를 나타내는 지표입니다.
SDXL-Lightning 모델은 높은 해상도의 세부 정보를 보다 잘 보존하면서도, 다른 방법들과 비교하여 다양성과 텍스트 정렬 측면에서는 비슷한 성능을 유지하고 있다는 것을 나타냅니다.
SDXL-Lightning 설치 방법
다음은 SDXL-Lightning 설치 방법입니다. SDXL-Lightning 실행을 위해서는 스테이블 디퓨전을 실행하기 위한 WebUI Auomatic1111 또는 ComfyUI가 필요합니다. 여기서는 ComfyUI를 사용하였습니다.
ComfyUI 설치
우선 피노키오 AI 브라우저를 이용해서 스테이블 디퓨전 실행을 위한 ComfyUI를 설치해 줍니다. 피노키오는 다양한 AI 도구를 손쉽게 설치하도록 도와주는 브라우저입니다. 다운로드 링크에서 피노키오 AI를 다운로드 후 설치하면 Discover 메뉴에서 ComfyUI를 원클릭으로 설치할 수 있습니다.


SDXL-Lightning LoRA 및 모델 다운로드
다음은 SDXL-Lightning의 LoRA 파일을 다운로드하여 ComfyUI의 C:\Users\사용자이름\pinokio\api\comfyui.git\app\models\loras 폴더에 복사합니다. LoRA 파일은 아래 링크에서 원하는 1, 2, 4, 8 step의 파일을 다운로드할 수 있으며, 저는 4 step의 "sdxl_lightning_4step_lora.safetensors" 파일을 다운로드하였습니다.
https://huggingface.co/ByteDance/SDXL-Lightning/tree/main
ByteDance/SDXL-Lightning at main
huggingface.co
다음은 스테이블 디퓨전에서 사용할 기본 모델 "Juggernaut XL"을 아래 링크에서 다운로드하여
C:\Users\사용자이름\pinokio\api\comfyui.git\app\models\checkpoints 폴더에 복사합니다.
https://civitai.com/models/133005/juggernaut-xl
Juggernaut XL - V9 + RunDiffusionPhoto 2 | Stable Diffusion Checkpoint | Civitai
For business inquires, commercial licensing, custom models, and consultation contact me under juggernaut@rundiffusion.com Juggernaut is available o...
civitai.com
ComfyUI 실행 및 이미지 생성
ComfyUI 실행은 피노키오 AI 브라우저에서 ComfyUI 아이콘을 클릭하고 화면 좌측의 Start를 클릭하면 http://127.0.0.1:8188/ 주소에서 ComfyUI 메인 화면이 열립니다. 다음은 ComfyUI에서 사용할 워크플로우를 아래 파일을 클릭하여 다운로드하고 화면 우측의 ComfyUI Manager 메뉴에서 Load를 클릭하여 불러옵니다


좌측 Load Checkpoint에서 노드를 클릭하여 이전 단계에서 다운로드한 "juggernautXL_v9Rundiffusionphoto2.safetensors"를 클릭해서 기본 모델을 선택합니다. 다음은 Load Checkpoint 바로 아래 LoraLoaderModelOnly 노드를 클릭해서 "sdxl_lightning_4step_lora.safetensors"를 선택합니다.
다음은 두 개의 CLIP Text Encode 노드 중 위쪽 Positive Prompt에 생성하고자 하는 이미지의 프롬프트를 입력하고 아래쪽 Negative Prompt에는 아래 더 보기를 클릭하여 나오는 것과 같이 원하지 않는 프롬프트를 입력합니다.
bad teeth, malformed bad fingers, malformed eyes, bloodshot eyes, bad anatomy, bad hands, three hands, three legs, bad arms, missing legs, missing arms, poorly drawn face, bad face, fused face, cloned face, worst face, three crus, extra crus, fused crus, worst feet, three feet, fused feet, fused thigh, three thigh, fused thigh, extra thigh, worst thigh, missing fingers, extra fingers, ugly fingers, long fingers, horn, extra eyes, huge eyes, 2girl, amputation, disconnected limbs, cartoon, cg, 3d, unreal, animate, bad fangs, crooked teeth, misaligned teeth, no tears, bad eyeline, milky eyes, urgly teeth
모두 입력이 끝나면 Manager 메뉴에서 Queue Prompt를 클릭하여 이미지 생성을 시작합니다. 그럼 아래와 같이 이미지가 생성되는 것을 확인하실 수 있습니다.



아래 동영상은 SDXL-Lightning CpmfyUI 실행영상으로, Queue Prompt를 클릭하고 3~4초 정도면 이미지가 생성됩니다. SDXL 모델 로딩은 최초 한번만 실행되며, 샘플링 소요시간은 시스템 성능에 따라 다를수 있습니다.
|
|
아래 이미지들은 SDXL-Lightning 모델을 이용해서 생성한 이미지들입니다.
















다음 이미지들은 논문에 제시된 프롬프트를 입력해서 생성한 결과입니다.
 |
 |
| A close-up of an Asian lady with sunglasses. | A monkey making latte art. |
 |
 |
| A delicate porcelain teacup sits on a saucer, its surface adorned with intricate blue patterns. | The 90s, a beautiful woman with a radiant smile and long hair, dressed in summer attire. |
 |
 |
| A majestic lion stands proudly on a rock, overlooking the vast African savannah. | A tanned woman, dressed in sportswear and sunglasses, climbing a peak with a group during the summer |

마치며
이 블로그에서는 ByteDance에서 개발한 SDXL-Lightning이라는 이미지 생성 모델에 대해 알아보았습니다. SDXL-Lightning은 점진적 적대적 확산 증류라는 새로운 접근 방식을 통해 한 단계 또는 몇 단계의 샘플링만으로 이미지를 생성할 수 있으며, 이를 통해 빠른 속도로 더 높은 품질의 이미지를 생성할 수 있습니다.
ComfyUI를 사용하여 SDXL-Lightning을 실행하고, 이미지를 생성하는 과정에서 논문에 제시된 프롬프트를 이용하여 어떤 이미지가 생성되는지 살펴보았으며, 기존의 SDXL 보다 빠른 생성속도를 체감할 수 있었습니다. SDXL-Lightning은 이미지 생성 분야에서 새로운 기술을 제시하고, 높은 품질의 이미지를 생성할 수 있는 가능성을 보여줍니다. 여러분도 한번 SDXL-Lightning의 빠른 생성속도를 한번 체험해 보시면 어떨까요? 오늘 내용은 여기까지입니다. 저는 다음에 더 유익한 자료를 가지고 다시 찾아뵙겠습니다. 감사합니다.
2024.02.17 - [대규모 언어모델] - Sora: 현실 세계를 시뮬레이션하는 OpenAI 비디오 생성 모델
Sora: 현실 세계를 시뮬레이션하는 OpenAI 비디오 생성 모델
안녕하세요! 오늘은 OpenAI에서 어제 공개한 새로운 생성형 AI 모델 Sora에 대해서 알아보겠습니다. Sora는 다양한 길이, 종횡비 및 해상도를 가진 비디오 및 이미지를 생성할 수 있는 시각 데이터 모
fornewchallenge.tistory.com
'AI 논문 분석' 카테고리의 다른 글
| MM1: 애플의 새로운 멀티모달 언어 모델 (0) | 2024.03.21 |
|---|---|
| [AI 논문] EMO: 사진 1장과 음성으로 되살린 오드리 헵번의 생생한 표정! (2) | 2024.02.28 |
| 뤼미에르: 구글의 텍스트 기반 비디오 생성의 새로운 기준 (4) | 2024.02.08 |
| OLMo(Open Language Model) : 완전한 오픈소스 대형 언어 모델 (0) | 2024.02.04 |
| [AI 논문] InstantID: 얼굴 사진 한장으로 딥페이크 생성 (0) | 2024.02.02 |




