목차
안녕하세요! 오늘은 LangChain, CrewAI를 활용해서 사용자가 요청한 키워드와 관련된 뉴스 기사를 인터넷에서 검색하고, 분석, 요약, 작성하는 과정을 자동화하는 방법을 알아보겠습니다. LangChain은 언어 모델 기반 응용 프로그램을 개발하기 위한 종합적인 프레임워크이며, CrewAI는 역할을 가진 자율 AI 에이전트들이 협력해서 복잡한 작업을 처리하도록 해줍니다. 이 블로그에서는 AI 에이전트 및 작업 정의, 협업 프로세스 관리, 텍스트 스플리팅과 임베딩, 유사도 검색과 외부 데이터 및 API 사용방법 등을 확인하실 수 있습니다.

LangChain이란?
LangChain은 언어 모델을 기반으로 하는 응용 프로그램을 개발하기 위한 종합적인 프레임워크입니다. 이 프레임워크는 다음과 같은 핵심 기능을 제공합니다.
- 문맥을 고려한 인공 지능 구축: LangChain은 언어 모델을 특정 문맥에 연결하여 문제 해결 및 결정을 지원합니다. 이는 언어 모델이 주어진 상황에 맞게 적합한 답변이나 행동을 생성할 수 있도록 돕는 것을 의미합니다. 예를 들어, 주어진 질문이나 상황에 따라 다른 응답을 생성하도록 모델을 조정할 수 있습니다.
- 추론 능력 강화: LangChain은 언어 모델을 기반으로 한 추론 시스템을 제공하여 사용자가 주어진 문맥에 따라 모델의 답변이나 행동을 예측하고 이해할 수 있도록 합니다. 이를 통해 모델이 왜 특정한 응답을 생성했는지 이해하고 모델의 작동 원리를 파악할 수 있습니다.
- 다양한 라이브러리 및 도구 제공: LangChain은 Python 및 JavaScript 라이브러리를 포함하여 다양한 도구와 구성 요소를 제공합니다. 이러한 도구와 구성 요소를 사용하면 응용 프로그램을 빠르게 개발하고 사용자 정의할 수 있습니다.
- 미리 제작된 체인 및 에이전트 제공: LangChain에는 고수준 작업을 수행하기 위한 미리 제작된 체인과 에이전트가 포함되어 있습니다. 이러한 미리 제작된 구성 요소를 사용하면 응용 프로그램을 빠르게 구축할 수 있습니다.
- LangServe를 통한 간편한 API 배포: LangChain은 LangServe를 사용하여 개발된 체인을 간편하게 API로 배포할 수 있습니다. 이를 통해 다른 시스템이나 서비스에서 쉽게 사용할 수 있습니다.
LangChain은 자연어 이해, 대화형 시스템, 정보 검색 및 추천 시스템과 같은 다양한 응용 프로그램에 적용할 수 있습니다. 이를 통해 개발자는 더 빠르고 효율적으로 인공 지능 기반의 응용 프로그램을 개발할 수 있습니다. 다음은 LangChain의 프레임워크를 나타낸 다이아그램입니다.

LangChain 프레임워크는 다음과 같은 여러 부분으로 구성됩니다:
- LangChain 라이브러리: Python 및 JavaScript 라이브러리로, 다양한 구성 요소에 대한 인터페이스와 통합을 포함합니다. 이 라이브러리에는 이러한 구성 요소를 체인과 에이전트로 결합하는 데 필요한 기본 실행 환경이 포함되어 있습니다. 또한, 다양한 작업을 수행하기 위한 미리 제작된 체인과 에이전트의 구현이 포함되어 있습니다.
- LangChain 템플릿: 다양한 작업에 대한 쉽게 배포 가능한 참조 아키텍처의 모음입니다. 이 템플릿은 특정 작업을 수행하는 데 필요한 구성 요소와 설정을 포함하고 있어, 사용자가 응용 프로그램을 빠르게 개발하고 사용자 정의할 수 있습니다.
- LangServe: LangChain 체인을 REST API로 배포하는 데 사용되는 라이브러리입니다. 이를 통해 LangChain으로 개발된 응용 프로그램을 다른 시스템과 통합하고, 외부에서 간편하게 사용할 수 있습니다.
- LangSmith: LangChain으로 빌드된 체인을 디버깅, 테스트, 평가 및 모니터링하는 개발자 플랫폼입니다. LangSmith를 사용하면 체인의 작동을 검사하고 최적화하여 성능을 향상시킬 수 있습니다. 또한, 이 플랫폼은 다양한 LLM(대형 언어 모델) 프레임워크와 원활하게 통합되어 사용자가 다양한 환경에서 체인을 개발하고 관리할 수 있도록 합니다.
위 구성요소 중 LangChain 라이브러리 자체는 여러 가지 다른 패키지로 구성됩니다.
- Langchain-core: 기본 추상화 및 LangChain 표현 언어가 포함되어 있습니다.
- Langchain-community: 써드파티 통합이 포함되어 있습니다.
- Langchain: 응용 프로그램의 인지 아키텍처를 구성하는 체인, 에이전트 및 검색 전략이 포함되어 있습니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
환경설정 및 라이브러리 설치
다음은 환경설정 및 라이브러리 설치단계입니다. 이 블로그의 모든 코드와 라이브러리 설치는 Ollama와의 호환성을 위하여 WSL(Windows Subsystem for Linux) 환경에서 실행되었습니다. Ollama는 현재 윈도우 프리뷰 버전이 공개되어 있지만, 아직 프리뷰 버전이라 저는 WSL에서 진행하였습니다. 라이브러리의 설치는 WSL 프롬프트에서 "python3.11 -m venv myenv" 명령어로 가상환경을 만들고 "source myenv/bin/activate" 명령어로 가상환경을 활성화한 다음, 아래 명령어를 입력하면 됩니다.
pip install crewai langchain-community langchain-openai requests duckduckgo-search chromadb gpt4all beautifulsoup4 newsapi-python
위 명령어로 설치되는 라이브러리에 대한 용도는 다음과 같습니다.
| 모듈 | 용도 |
| os | 운영 체제와 상호 작용 (환경 변수 설정/읽기) |
| requests | HTTP 요청/응답 (외부 API 데이터 요청) |
| crewai.Agent/Task/Crew/Process | Crew AI 에이전트/작업/크루/프로세스 정의 |
| langchain_core.retrievers.BaseRetriever | 정보 검색 및 처리 |
| langchain.tools.tool | Langchain 툴 정의 |
| langchain_community.document_loaders.WebBaseLoader | 웹 문서 로드 (뉴스 기사 등) |
| langchain.text_splitter.RecursiveCharacterTextSplitter | 텍스트 일정 크기 분할 |
| langchain_community.vectorstores.Chroma | 문서 임베딩 및 유사도 검색 |
| langchain_community.tools.DuckDuckGoSearchRun | 웹 검색 |
| langchain_community.embeddings.GPT4AllEmbeddings | GPT 모델 텍스트 임베딩 |
| langchain_community.chat_models.ChatOllama | 대화형 모델 상호 작용 |
| bs4.BeautifulSoup | HTML/XML 문서 파싱 |
파이썬 코드 실행
다음은 코드 실행단계인데요, 이 코드의 출처는 유튜브 "CrewAI RAG: How I Created AI Assistants to Run My News Agency"이며, 코드는 다음과 같은 프로세스를 통해 뉴스 기사를 검색하고 처리하여 요약하는 작업을 수행합니다. 이 코드의 동작순서는 다음과 같습니다.
- 환경 설정 및 필수 모듈 임포트: crewAI, langchain 등 필요한 라이브러리 및 모듈을 임포트 하고, 환경 변수를 설정하여 뉴스 API 키를 저장합니다.
- Embedding 설정: `embedding_function`은 GPT4AllEmbeddings 클래스의 인스턴스를 생성하여 사용됩니다. `llm`은 ChatOllama 클래스의 인스턴스를 생성하고 "mistral" 모델을 사용합니다.
- 도구 설정: `SearchNewsDB` 클래스는 뉴스 기사를 검색하고 처리하는 도구를 정의합니다. `GetNews` 클래스는 Chroma DB에서 관련 뉴스 정보를 검색하는 도구를 정의합니다. `DuckDuckGoSearchRun` 클래스는 웹에서 뉴스 기사를 검색하는 도구를 정의합니다.
- 에이전트 및 작업 생성: `news_search_agent`는 뉴스 검색 에이전트를 생성합니다. 주요 목표는 최신 뉴스 기사에서 각각의 주요 포인트를 생성하는 것입니다. `writer_agent`는 작성 에이전트를 생성합니다. 주요 목표는 받은 모든 주제를 식별하고, 각 주제를 검증하기 위해 Get News Tool을 사용하며, 각 주제에 대한 상세 탐색을 위해 검색 도구를 사용하고, 모든 주제에 대한 정보를 정리하는 것입니다.
- 작업 생성: `news_search_task`는 "Large Language Model"을 검색하고 각 뉴스 기사에 대한 주요 포인트를 생성하는 작업입니다. `writer_task`는 주제를 식별하고 검증하며, 각 주제에 대한 정보를 검색하고 정리하는 작업입니다.
- 크루 생성: 크루는 생성된 에이전트와 작업을 결합하여 실행되는 작업을 정의합니다. `news_crew`는 뉴스 검색 및 작성 에이전트, 뉴스 검색 및 작성 작업을 포함합니다. 이 크루는 순차적인 프로세스를 따릅니다.
- 크루 실행: `news_crew.kickoff()`을 호출하여 크루를 실행하고 결과를 출력합니다. 이러한 프로세스를 통해 뉴스 기사가 검색되고 처리되며, 최종적으로 요약된 정보를 생성합니다.
이 코드는 뉴스 기사를 가져오고 분석하여 관련 정보를 요약하고, 작성하는 과정을 자동화합니다.
import os
from newsapi import NewsApiClient # Importing NewsApiClient from newsapi-python library
from crewai import Agent, Task, Crew, Process
from langchain_core.retrievers import BaseRetriever
from langchain.tools import tool
from langchain_community.document_loaders import WebBaseLoader
import requests
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_community.tools import DuckDuckGoSearchRun
from langchain_community.embeddings import GPT4AllEmbeddings
from langchain_community.chat_models import ChatOllama
from bs4 import BeautifulSoup
embedding_function = GPT4AllEmbeddings()
llm = ChatOllama(model="mistral")
# Set up News API client with the provided API key
newsapi = NewsApiClient(api_key='발급받은 News.org key')
# Tool 1 : Save the news articles in a database
class SearchNewsDB:
@tool("News DB Tool")
def news(query: str):
"""Fetch news articles and process their contents."""
API_KEY = '989f91875aa64e29b75090f8e9d9051e' # Your NewsAPI API key
base_url = "https://newsapi.org/v2/everything"
params = {
'q': query,
'sortBy': 'publishedAt',
'apiKey': API_KEY,
'language': 'en',
'pageSize': 5,
}
response = requests.get(base_url, params=params)
if response.status_code != 200:
return "Failed to retrieve news."
articles = response.json().get('articles', [])
all_splits = []
for article in articles:
# Assuming WebBaseLoader can handle a list of URLs
loader = WebBaseLoader(article['url'])
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
all_splits.extend(splits) # Accumulate splits from all articles
# Index the accumulated content splits if there are any
if all_splits:
vectorstore = Chroma.from_documents(all_splits, embedding=embedding_function, persist_directory="./chroma_db")
retriever = vectorstore.similarity_search(query)
return retriever
else:
return "No content available for processing."
# Tool 2 : Get the news articles from the database
class GetNews:
@tool("Get News Tool")
def news(query: str) -> str:
"""Search Chroma DB for relevant news information based on a query."""
vectorstore = Chroma(persist_directory="./chroma_db", embedding_function=embedding_function)
retriever = vectorstore.similarity_search(query)
return retriever
# Tool 3 : Search for news articles on the web
search_tool = DuckDuckGoSearchRun()
# 2. Creating Agents
news_search_agent = Agent(
role='News Seacher',
goal='Generate key points for each news article from the latest news',
backstory='Expert in analysing and generating key points from news content for quick updates.',
tools=[SearchNewsDB().news],
allow_delegation=True,
verbose=True,
llm=llm
)
writer_agent = Agent(
role='Writer',
goal='Identify all the topics received. Use the Get News Tool to verify the each topic to search. Use the Search tool for detailed exploration of each topic. Summarize the retrieved information in depth for every topic.',
backstory='Expert in crafting engaging narratives from complex information.',
tools=[GetNews().news, search_tool],
allow_delegation=True,
verbose=True,
llm=llm
)
# 3. Creating Tasks
news_search_task = Task(
description='Search for "OpenAI Sora" and create topics for each news.',
agent=news_search_agent,
tools=[SearchNewsDB().news]
)
writer_task = Task(
description="""
Go step by step.
Step 1: Identify all the topics received.
Step 2: Use the Get News Tool to verify the each topic by going through one by one.
Step 3: Use the Search tool to search for information on each topic one by one.
Step 4: Go through every topic and write an in-depth summary of the information retrieved.
Don't skip any topic.
""",
agent=writer_agent,
context=[news_search_task],
tools=[GetNews().news, search_tool]
)
# 4. Creating Crew
news_crew = Crew(
agents=[news_search_agent, writer_agent],
tasks=[news_search_task, writer_task],
process="sequential",
manager_llm=llm
)
# Execute the crew to see RAG in action
result = news_crew.kickoff()
print(result)
"OpenAI Sora"에 대한 뉴스 검색, 분석, 요약을 요청한 코드의 실행결과는 다음과 같습니다.
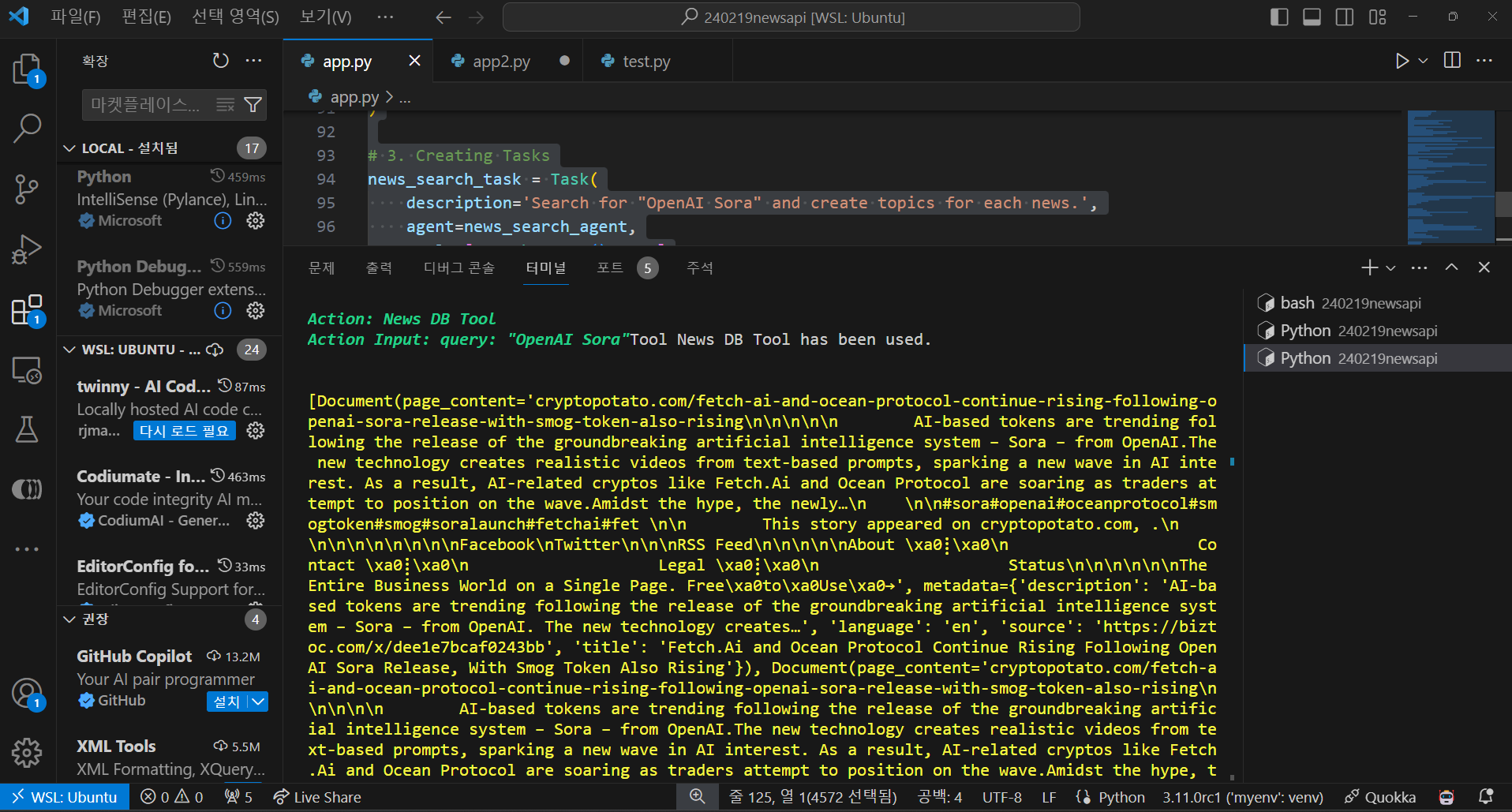

요약: 선도적인 인공지능 연구 연구소인 OpenAI는 최근에 Sora라는 새로운 텍스트 대 비디오 모델을
클로즈드 베타로 출시했습니다. 이 모델은 현실적인 감정과 부드러운 전환을 갖는 비디오를 생성하는
능력으로 인해 상당한 주목을 받고 있습니다. OpenAI의 CEO 인 Sam Altman은 또한 글로벌 AI 칩 제조
능력을 향상시키기 위해 기관에 상당한 자금을 모으기 위한 협상을 진행 중이라고 보도되고 있습니다.
그러나 중요한 점은 Altman과 관련된 다른 프로젝트인 Worldcoin이 홍채인식 작업과 여러 정부의
조사로 인해 논란에 휩싸였다는 것입니다. OpenAI의 Sora 텍스트 대 비디오 모델 출시와 Sam Altman의
투자자와의 협상에 관한 정보 요약을 제공했던 것으로 보입니다. 그러나 Altman과 연관된 또 다른
프로젝트인 Worldcoin은 Altman이 이끌고 있지만, 별개의 프로젝트이며 혼동해서는 안 됩니다.
마치며
이 블로그에서는 LangChain과 CrewAI를 활용하여 사용자가 원하는 키워드와 관련된 뉴스 기사를 자동으로 검색, 분석, 요약하는 과정을 자세히 살펴보았습니다. LangChain은 언어 모델을 기반으로 한 종합적인 프레임워크로, 문맥을 고려한 인공 지능 구축부터 다양한 라이브러리 및 도구 제공까지 다양한 기능을 제공합니다. CrewAI는 역할을 가진 자율 AI 에이전트들이 협력하여 복잡한 작업을 처리할 수 있도록 해주는 플랫폼입니다.
이 블로그를 통해 코드 실행 과정부터 LangChain 프레임워크의 구성요소와 CrewAI를 사용한 작업 정의까지를 자세히 살펴보았으며, 또한, 코드의 실행결과로 OpenAI의 Sora 텍스트 대 비디오 모델 출시와 Sam Altman의 투자자와의 협상에 관한 뉴스 요약도 확인하였습니다. LangChain과 CrewAI를 활용한 자동화된 뉴스 검색 및 요약 과정은 다양한 정보를 신속하게 처리하고 요약하는 데 도움이 될 수 있을 것 같습니다.
오늘 내용은 여기까지입니다. 그럼 저는 다음에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.
2024.02.18 - [AI 도구] - 엔비디아의 최신 DEMO: Chat with RTX 설치 및 사용후기
엔비디아의 최신 DEMO: Chat with RTX 설치 및 사용후기
안녕하세요! 오늘은 최근 엔비디아에서 공개한 "Chat with RTX"의 설치 및 사용후기에 대해 작성해 보겠습니다. "Chat with RTX"는 사용자가 자신의 문서, 노트, 비디오 또는 기타 데이터에 연결된 GPT(Gene
fornewchallenge.tistory.com
'AI 도구' 카테고리의 다른 글
| 🏆텍스트 임베딩의 혁신! 오픈AI 뛰어넘은 노믹 임베드의 모든것! (2) | 2024.02.25 |
|---|---|
| 💥핵꿀팁! 스마트폰에서 Ollama WebUI를 만나는 방법 (ngrok 활용) (0) | 2024.02.21 |
| 엔비디아의 최신 DEMO: Chat with RTX 설치 및 사용후기 (2) | 2024.02.18 |
| 🚀Ollama와 Instructor를 활용한 대규모 언어 모델과의 상호 작용 가이드 (0) | 2024.02.15 |
| AutoGen: 토큰 과금 없는 100% 무료 대규모 언어 모델 협업 자동화 (2) | 2024.02.13 |




