목차
안녕하세요! 오늘은 최근 엔비디아에서 공개한 "Chat with RTX"의 설치 및 사용후기에 대해 작성해 보겠습니다. "Chat with RTX"는 사용자가 자신의 문서, 노트, 비디오 또는 기타 데이터에 연결된 GPT(Generative Pre-trained Transformer) 대규모 언어 모델(LLM)을 개인화할 수 있는 DEMO 앱입니다. 검색 확장 생성(RAG), TensorRT-LLM 및 RTX 가속을 활용하여 사용자는 사용자 정의 챗봇에 쿼리 하여 즉각적으로 맥락에 맞는 답변을 얻을 수 있습니다. 그리고 이 모든 것이 로컬로 실행되므로 빠르고 안전한 결과를 얻을 수 있습니다. 이 블로그에서는 "Chat with RTX" 설치방법과 에러 해결방법, 특징과 장단점 등에 대해 알아보겠습니다.

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
시스템 요구사양
"Chat with RTX"를 설치하고 구동하기 위한 PC의 사양은 다음과 같습니다. 현재는 운영체제는 윈도우만 지원되고 있으며, GPU는 RTX 30 또는 40 시리즈 VRAM 8GB 이상, PC RAM은 16GB 이상을 요구하고 있습니다.

다음은 제 PC와 그래픽카드의 사양입니다. CPU는 인텔 i9-13900H이고, RAM은 16GB, 윈도우 11 Pro 23H2입니다.
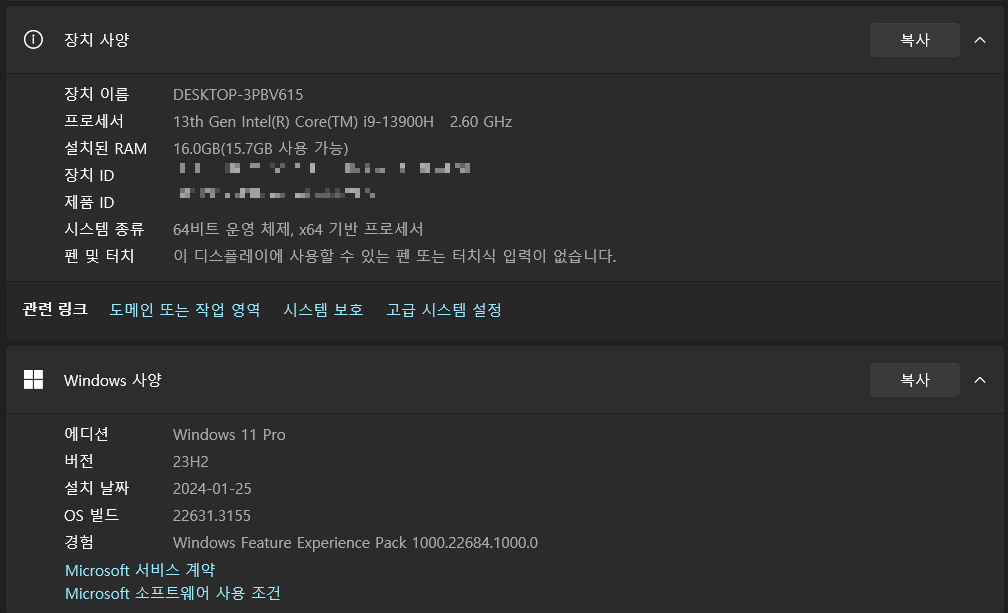
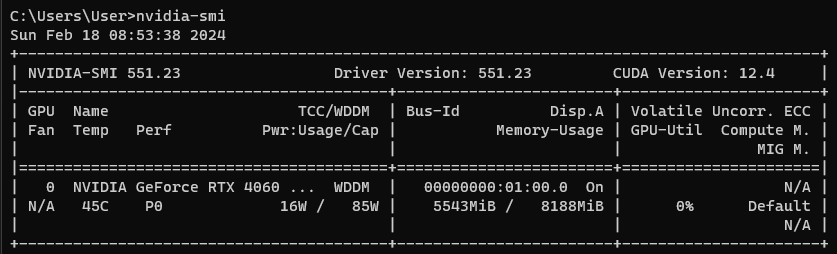
그래픽카드는 NVIDIA GeForce RTX 4060이며 정보는 다음과 같습니다.
- NVIDIA 그래픽 드라이버의 버전: 551.23
- CUDA(Compute Unified Device Architecture) 버전: 12.4
- Memory: 8GB (VRAM용량에 따라 Llama2 모델은 설치되지 않을 수 있습니다.-본문 아래 내용 참고)
설치 및 에러 해결방법
다음은 "Chat with RTX" 설치 및 에러 해결방법입니다. 설치파일은 아래 링크에서 다운로드하시면 됩니다. 설치파일의 용량은 약 35GB입니다. (Mistral 약 13GB, Llama2 약 24GB)
https://www.nvidia.com/en-us/ai-on-rtx/chat-with-rtx-generative-ai/
NVIDIA Chat With RTX
Your Personalized AI Chatbot.
www.nvidia.com
다운로드한 설치파일의 압축을 풀고, setup.exe를 실행하면 소프트웨어 라이센스 동의화면이 나옵니다.
다음을 누르면 설치가 진행되고, 저의 경우총 설치시간은 약 15~20분 정도 소요된 것 같습니다.
설치가 완료되고 바탕화면의 NVIDIA Chat with RTX 아이콘을 실행하면 됩니다. 하지만 저의 경우에는 아래화면과 같이 "Invalid session"에러가 발생하였습니다.

구글 검색결과 엔비디아 개발자 포럼을 통해 에러발생에 대한 조치방법을 찾을 수 있었습니다. 엔비디아에서는 디폴트 설치경로를 바꾸지 말라고 조치방법을 알려주었지만 저의 경우는 이 방법으로는 해결되지 않았습니다.
저의 경우 아래 게시판의 내용을 참고하여 에러를 해결하였습니다. 조치방법은 AppData\Local\NVIDIA\ChatWithRTX\RAG\trt-llm-rag-windows-main\ui\user_interface.py 파일의 쿠키 관련 내용을 아래와 같이 수정하는 내용입니다. 들여 쓰기와 '' 기호에 주의하여 비주얼 스튜디오 코드 등을 이용하여 파일을 수정한 후 다시 실행하면 됩니다.
Chat with RTX "Invalid session. Reopen RTX Chat from desktop to continue chatting."
I don’t really know what is the deeper issue that is causing this bug, or if it’s just that nvidia didn’t catch the bug. anyway, the following fixes the surface issue and allows the interface to open properly: First find this file: C:\Users\{Your use
forums.developer.nvidia.com
C:\Users\{Your user dir}\AppData\Local\NVIDIA\ChatWithRTX\RAG\trt-llm-rag-windows-main\ui\user_interface.py
Find the context of line 298.
Place the following line of code:
key, value = cookie.split('=')
Replace with:
split_index = cookie.find('=')
key, value = cookie[:split_index], cookie[split_index+1:]Chat with RTX 실행
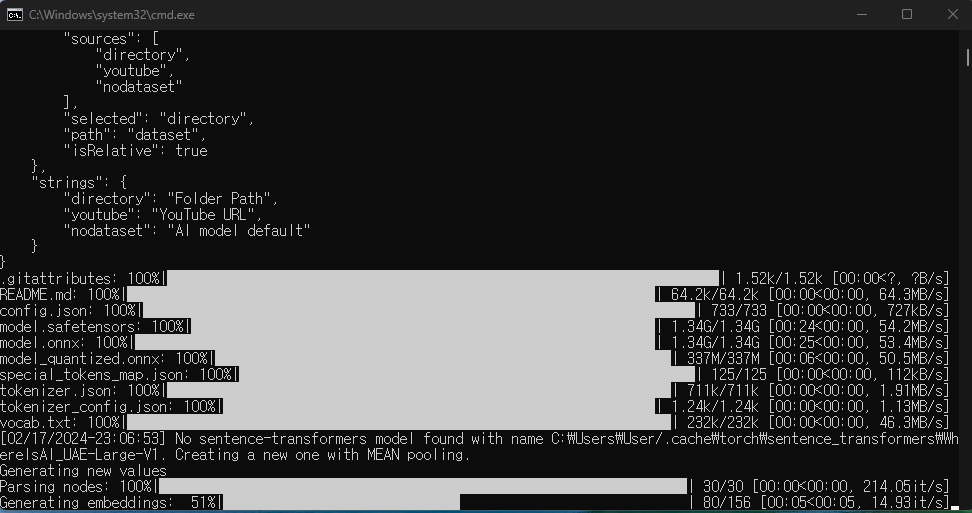
최초 기동시에는 아래와 같이 모델 관련 파일이 다운로드되며, 완료 후 "http://127.0.0.1:37018/?__theme=dark" 주소에서 Chat with RTX 메인화면이 웹브라우저를 통해 열리게 됩니다.
메인화면
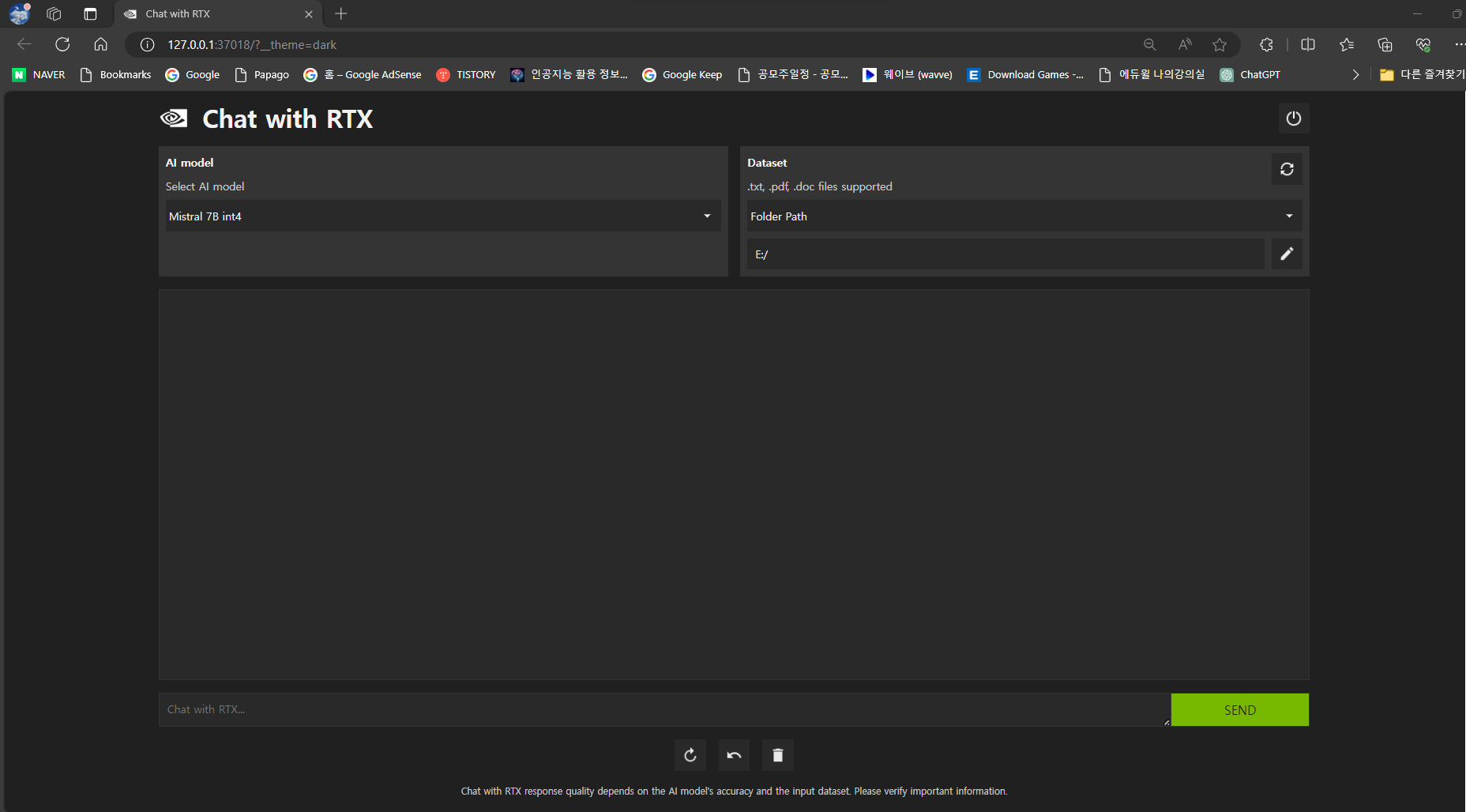
메인화면은 아래 화면과 같습니다. 상단 좌측은 언어 모델을 선택할 수 있는 드롭다운 메뉴가 있고 상단 우측에는 PC의 폴더를 지정하는 UI가 있습니다. 하단에는 사용자가 텍스트를 입력할 수 있는 입력창과 SEND 버튼이 있습니다.
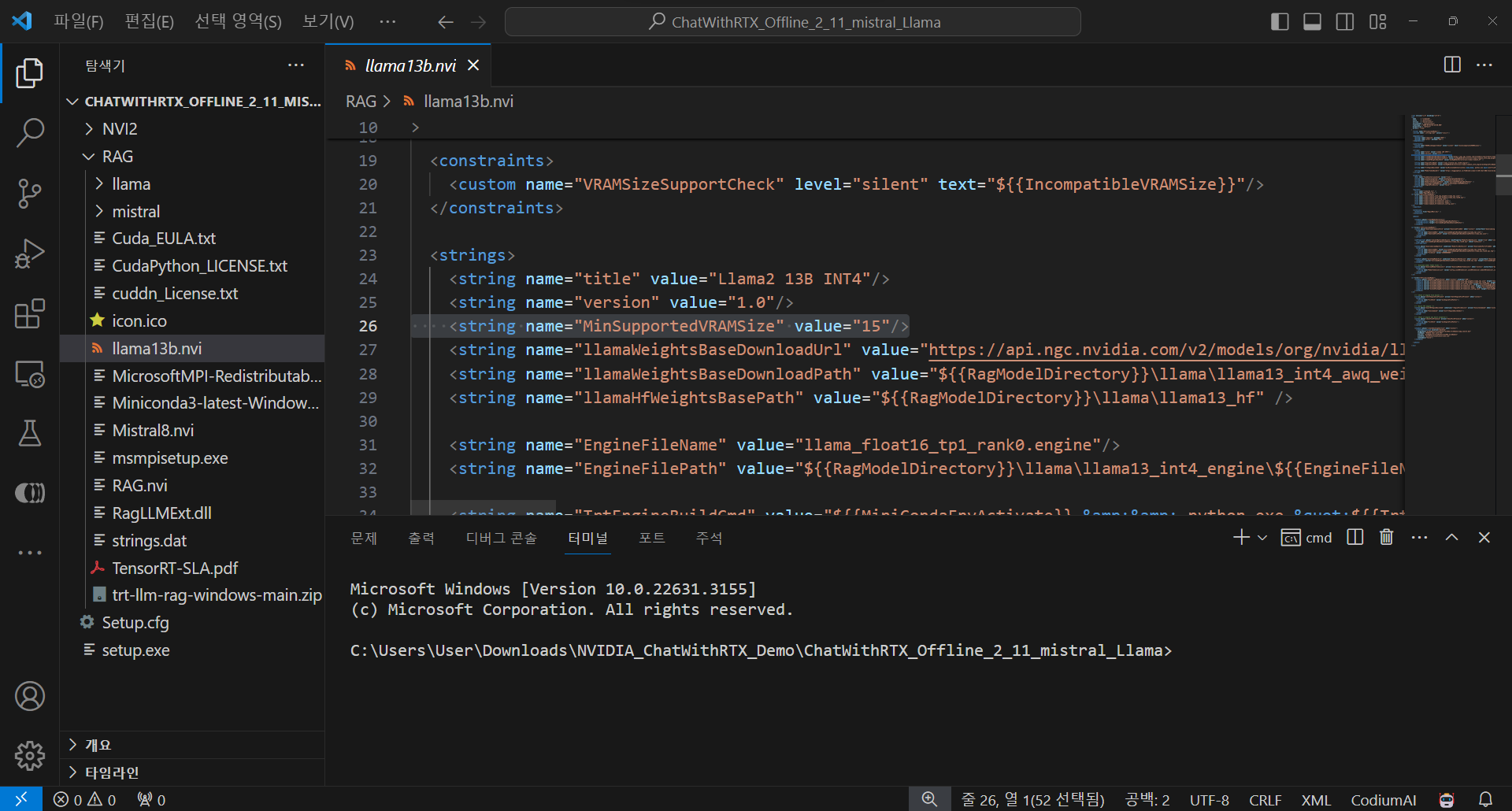
언어 모델을 선택할 수 있는 드롭다운 메뉴에 나타나는 모델은 사용자 PC의 사양과 설치파일의 경로에 존재하는 파일(NVIDIA_ChatWithRTX_Demo\ChatWithRTX_Offline_2_11_mistral_Llama\RAG\llama13b.nvi)의 설정에 따라 다를 수 있습니다. Llama2는 15GB 이상의 VRAM에서만 다운로드되고 실행가능하며, 아래 화면과 같이 설치파일에 포함된 llama13b.nvi 파일의 "MinSupportedVRAMSize"를 변경하여 설치하는 방법이 있지만 저는 시도하지 않았습니다.
RAG 기능
RAG(Retrieval-Augmented Generation, 검색증강생성)는 대규모 텍스트 데이터를 기반으로 작동하며, 이를 사용하여 질문에 대한 정보를 검색하고, 해당 정보를 기반으로 질문에 대한 답변을 생성하는 기술입니다. 우측 상단에서 PC의 폴더를 지정하면 폴더 내 txt, pdf, doc 문서들의 벡터 엠베딩이 생성되고, 이 컨텍스트를 기반으로 Mistral 7B 언어 모델이 답변을 하게 됩니다.
Chat with RTX의 RAG 응답속도는 임베딩의 크기와 검색 대상 텍스트의 분량에 따라 다르겠지만 저의 경우 아래 동영상 화면과 같이 질문 입력 후 응답이 표시되는데 약 1~2초 소요되었으며, 사용에 불편은 없었습니다.
|
|
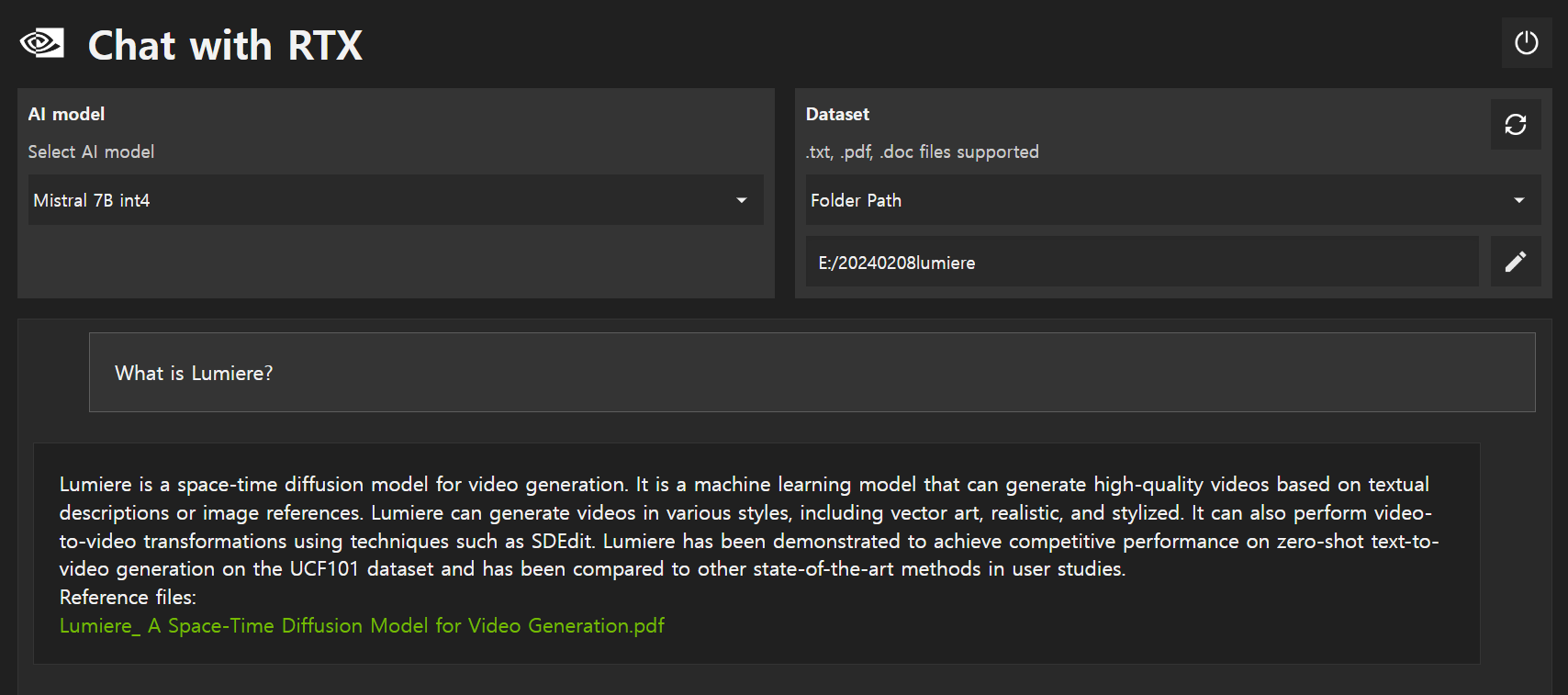
질문을 입력하면 아래 화면과 같이 참조 파일 바로가기와 함께 응답내용이 표시됩니다.
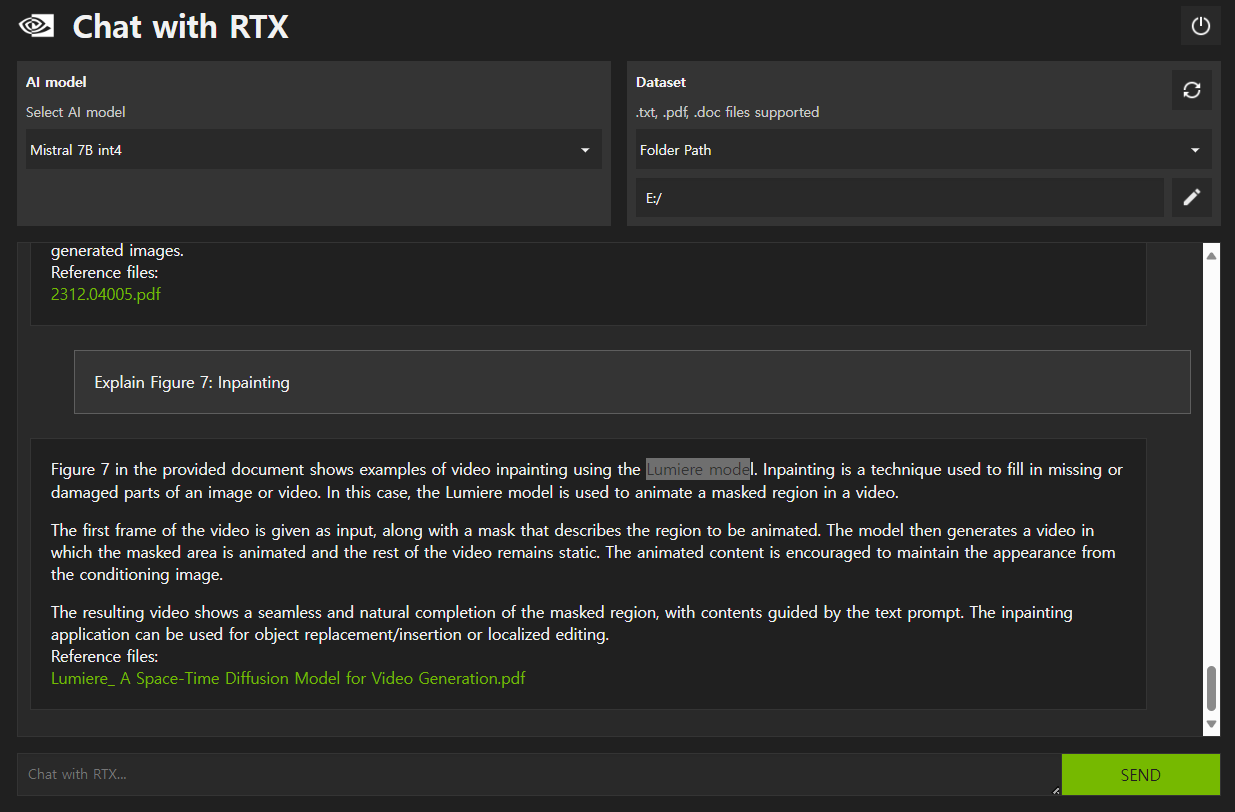
아래 화면을 보면 PDF 문서에 포함된 특정 그림에 대한 질문에도 잘 답변하는 것을 확인할 수 있습니다.
YouTube URL 대화기능
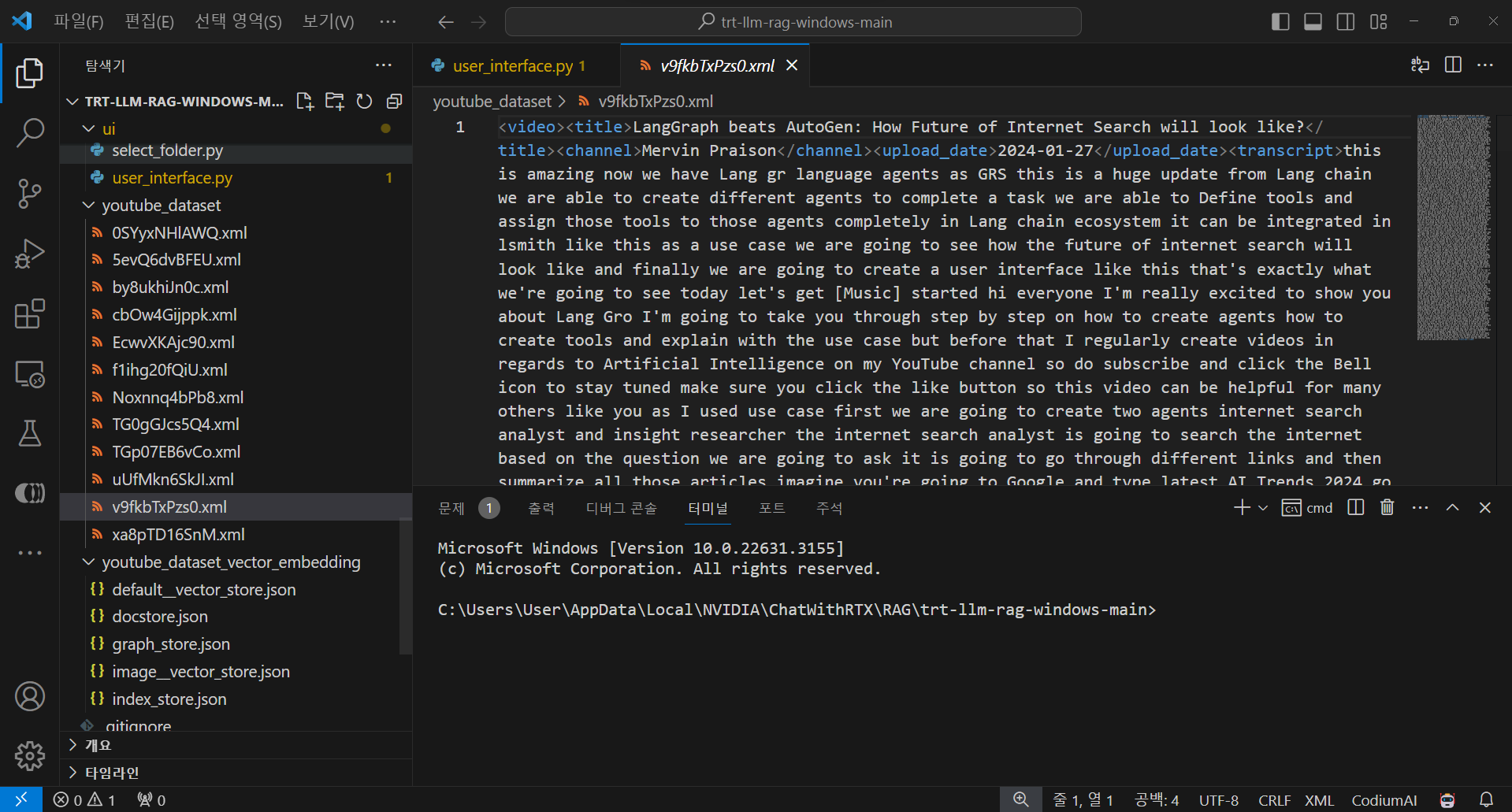
다음은 YouTube URL 대화기능입니다. Dataset 메뉴에서 YouTube URL을 선택하고 아래 칸에 YouTube 동영상 주소를 입력한 후, 오른쪽 "Download scripts" 버튼을 클릭하면 스크립트를 다운로드하게 되며, 아래 화면과 같이 "\AppData\Local\NVIDIA\ChatWithRTX\RAG\trt-llm-rag-windows-main\youtube_dataset" 폴더에 xml 형식으로 스크립트가 저장됩니다.
아래 화면과 같이 동영상의 내용을 설명해 달라고 하면 언어모델은 다운로드 한 스크립트를 참조하여 응답합니다.
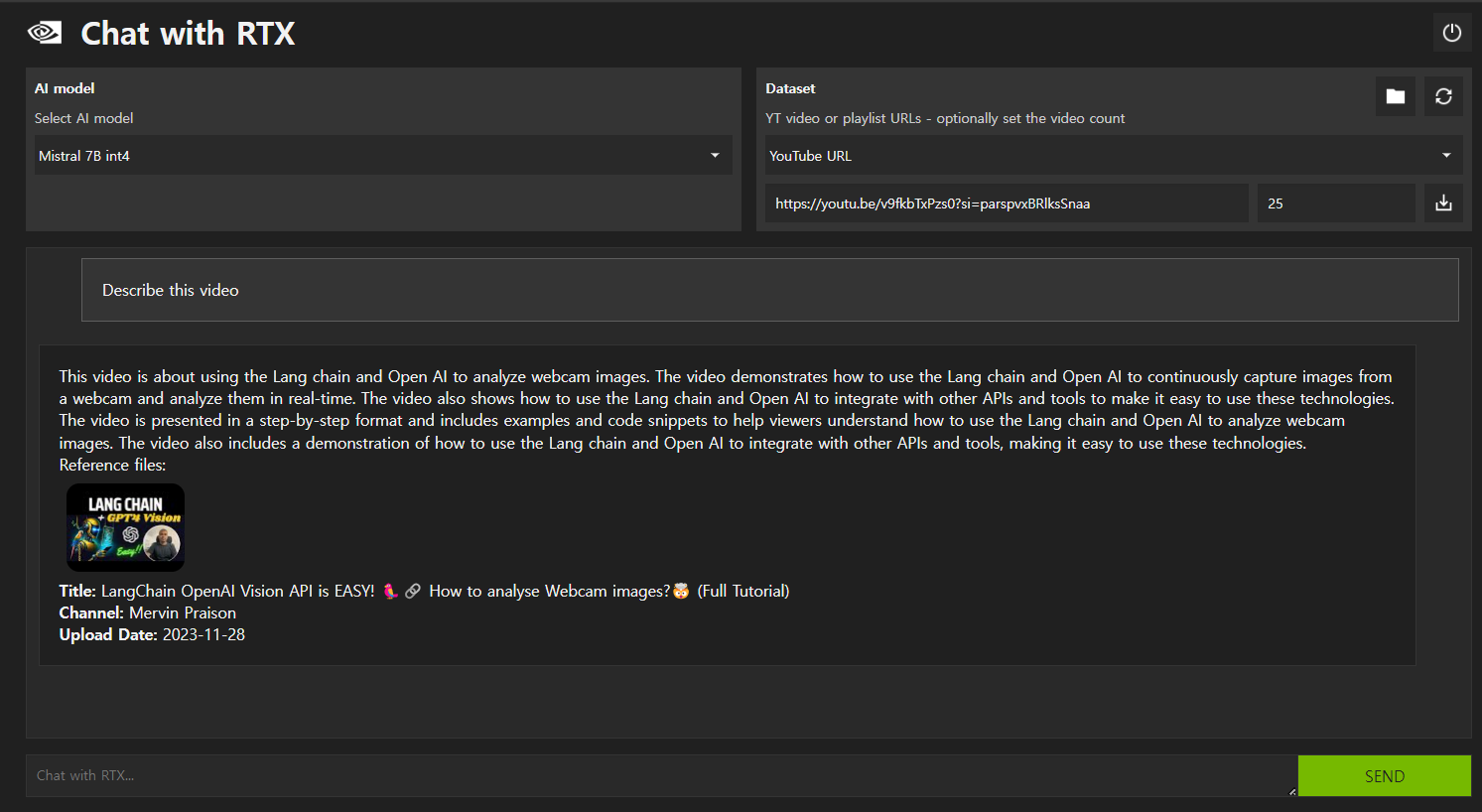
이 비디오는 Lang chain과 Open AI를 사용하여 웹캠 이미지를 분석하는 방법에 대한 것입니다.
이 비디오는 Lang chain과 Open AI를 사용하여 웹캠에서 이미지를 연속적으로 캡처하고 실시간으로
분석하는 방법을 보여줍니다. 또한 이 비디오는 Lang chain과 Open AI를 다른 API와 도구와 통합하여
이러한 기술을 쉽게 사용할 수 있도록 하는 방법을 보여줍니다. 이 비디오는 단계별로 설명하며 예제와
코드 조각을 포함하여 Lang chain과 Open AI를 사용하여 웹캠 이미지를 분석하는 방법을 이해할 수
있도록 도와줍니다. 이 비디오에는 Lang chain과 Open AI를 다른 API와 도구와 통합하여 이러한 기술을
쉽게 사용할 수 있도록 하는 데모도 포함되어 있습니다.기본 AI 모델 대화
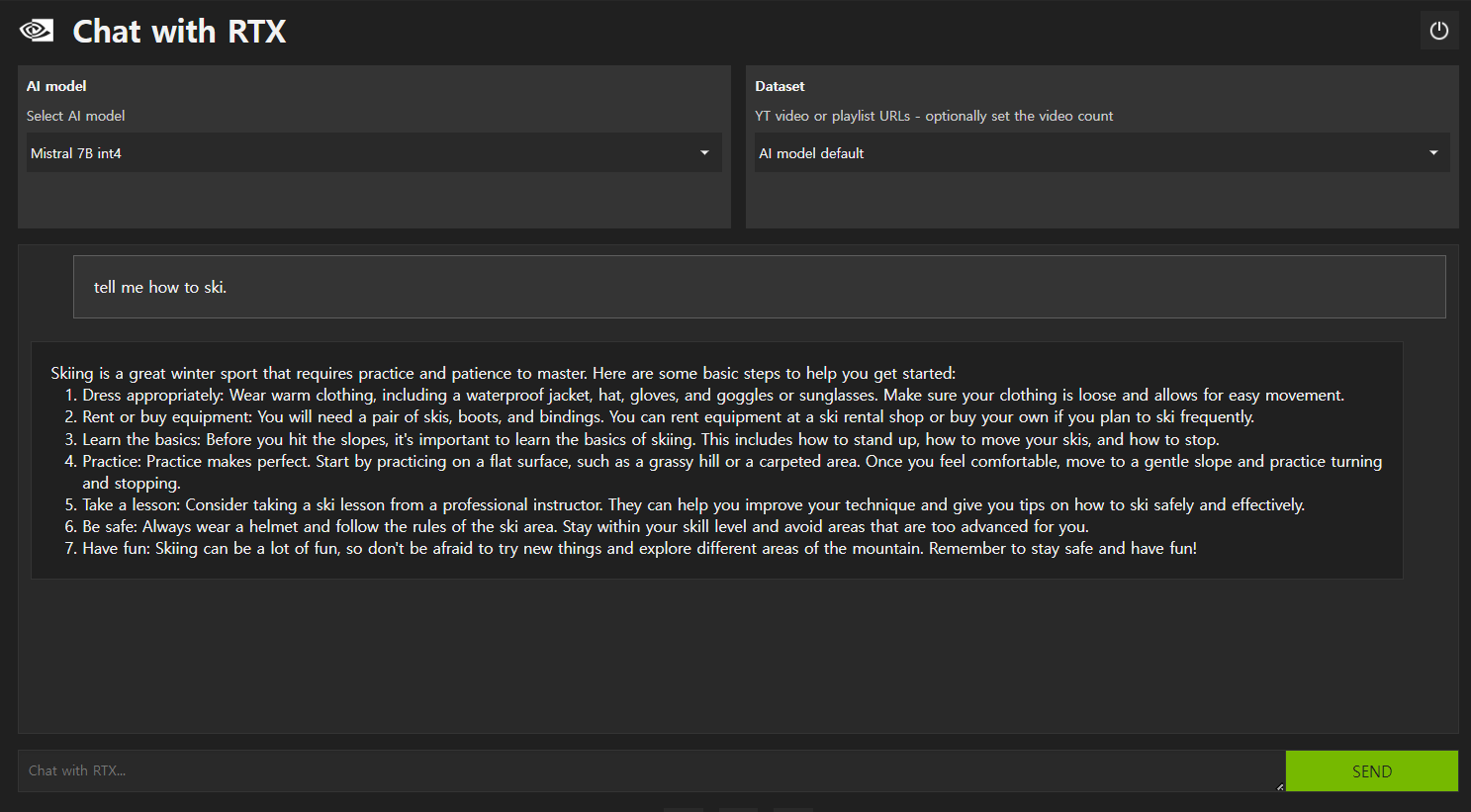
Dataset 메뉴에서 "AI model default" 기능을 선택하면 기본 AI 모델과 대화를 할 수 있으며, 저장된 텍스트나 유튜브 스크립트가 아닌 언어 모델이 사전에 학습한 내용에 기반하여 아래 화면과 같이 응답이 출력됩니다.
기타 개선 필요사항
Chat with RTX는 PC LLM이라는 로컬 대규모 언어 모델 활용을 구현하였지만, DEMO가 아닌 정식버전에서는 몇 가지 개선이 필요한 것으로 확인되었습니다.
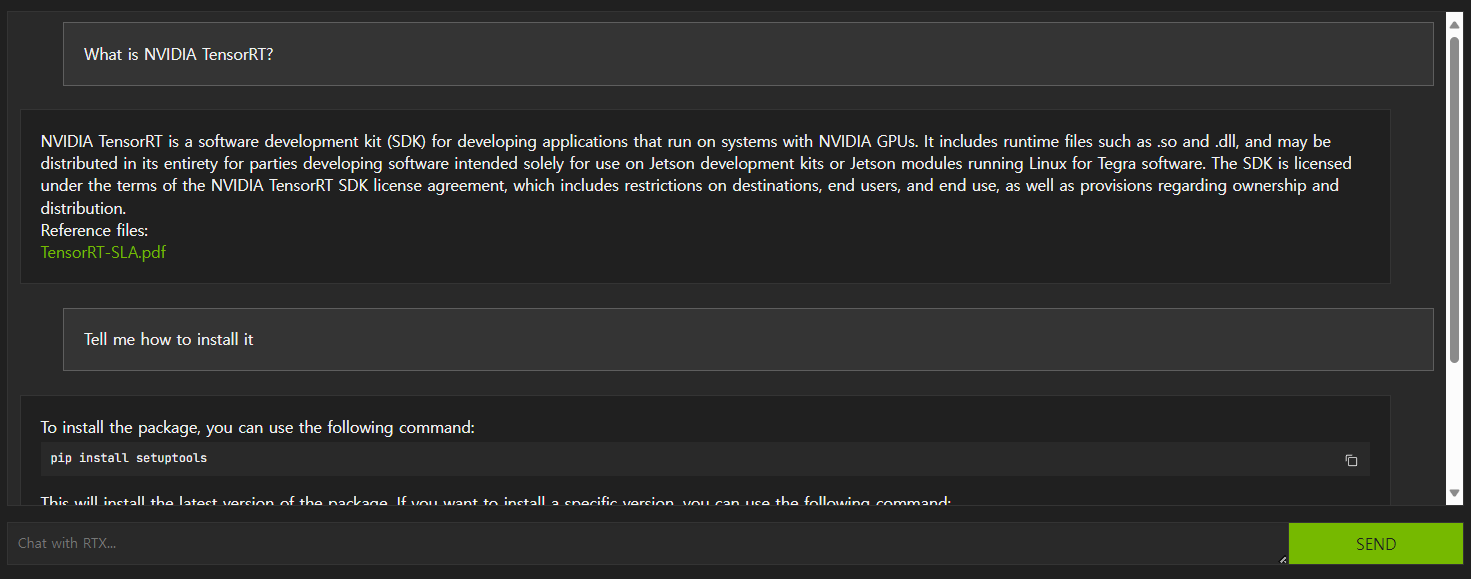
제일 중요한 것은 RAG에서 문맥을 이해하지 못한다는 것입니다. 첫 번째 질문에 이어지는 두 번째 질문에서 중복 내용을 생략하면 Chat with RTX는 이해하지 못합니다. 아래 화면을 보면 "What is NVIDIA TensorRT?"라는 질문에 이어지는 "Tell me how to install it"에는 전혀 다른 내용을 응답하고, "Tell me how to install NVIDIA TensorRT"라고 질문해야만 원하는 답변을 얻을 수 있습니다.
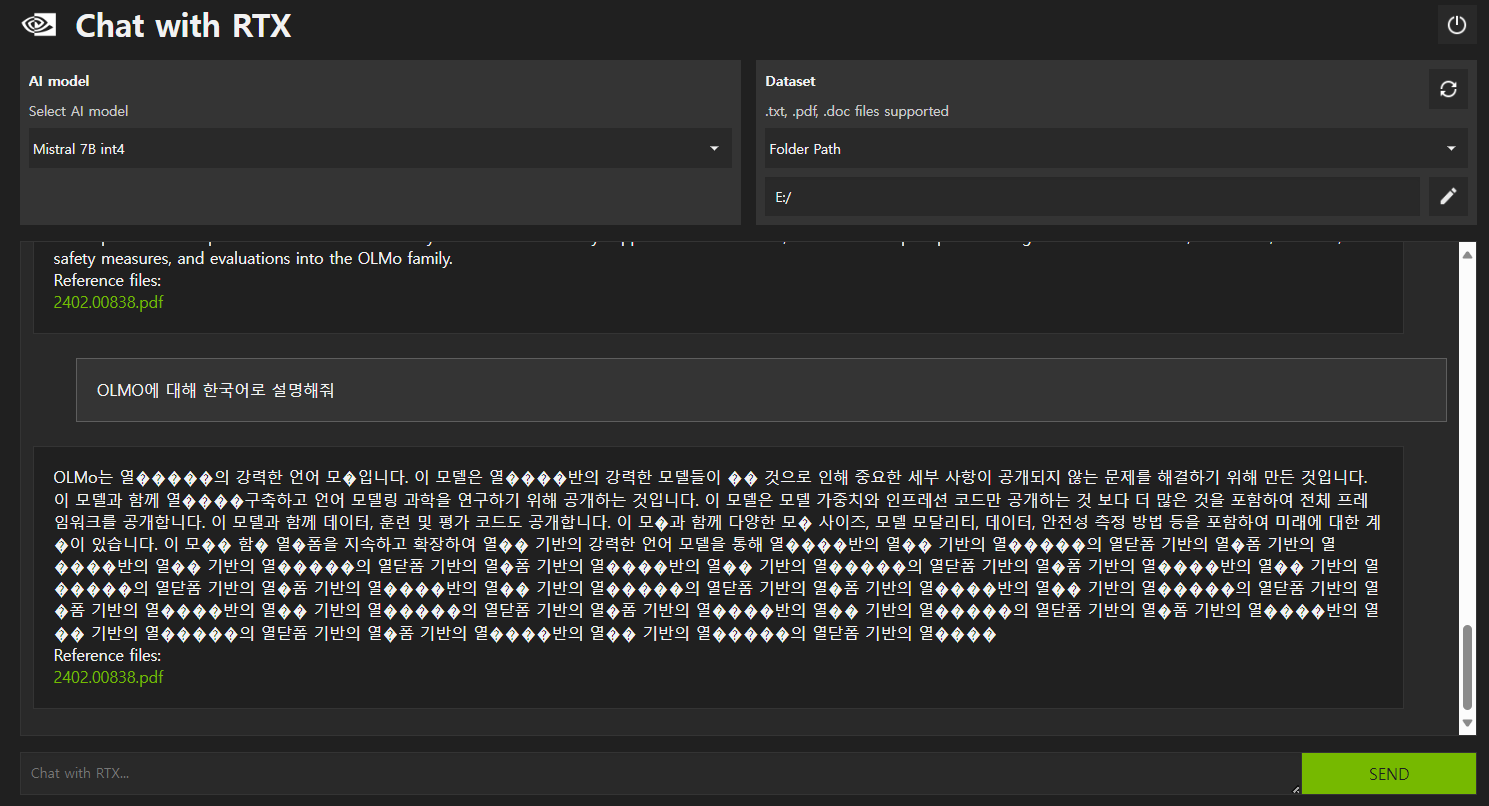
또한 아래 화면과 같이 한글은 지원이 되지 않으며, 비정상 응답내용 반복 현상이 발생합니다. 이것은 Mistral 7B 언어 모델이 한글을 지원하지 않기 때문인 것으로 생각됩니다.
또한 PC LLM을 표방하지만, PC의 로컬 드라이브에 저장된 텍스트 파일이 아닌 일반 파일은 인식하지 못합니다. 아래 화면에서 보면 제 PC의 E 드라이브에 있는 파일의 개수에 대해 응답하지 못하는 것을 알 수 있습니다.

또한 검색 대상파일이 추가되는 경우 "Refresh Dataset"을 클릭하여 일정 시간 동안 벡터 임베딩을 다시 생성해야 새로운 파일에 대해 대화가 가능한 것은 개선이 필요해 보입니다.


마치며
오늘은 엔비디아의 최신 기술 중 하나인 "Chat with RTX"의 설치 및 사용후기를 다뤄보았습니다. 이 솔루션은 오픈소스이며, 사용자가 자신의 데이터에 연결된 대규모 언어 모델을 개인화할 수 있는 DEMO 앱으로, 사용자 정의 챗봇을 통해 즉각적인 맥락에 맞는 답변을 얻을 수 있습니다.
이번 블로그에서는 시스템 요구사항과 설치 과정에 발생할 수 있는 에러에 대한 해결책과 함께 각 부분의 기능 및 특징을 상세히 설명하고, RAG(Retrieval-Augmented Generation) 기능을 통해 대규모 텍스트 데이터를 활용하여 답변을 생성하는 기술과 YouTube URL을 통한 대화 기능 등도 살펴보았습니다.
하지만 몇 가지 개선이 필요한 부분도 확인하였습니다. 문맥 이해 부분에서의 한계와 한글 미지원 등의 이슈가 있습니다. 또한 로컬 드라이브 일반 파일 미인식과 벡터 임베딩 재생성의 번거로움 등은 개선이 필요해 보입니다. 오늘 내용은 여기까지입니다. 저는 그럼 다음에 더욱 유익한 내용으로 다시 찾아뵙겠습니다. 감사합니다.
2024.02.17 - [대규모 언어모델] - Sora: 현실 세계를 시뮬레이션하는 OpenAI 비디오 생성 모델
Sora: 현실 세계를 시뮬레이션하는 OpenAI 비디오 생성 모델
안녕하세요! 오늘은 OpenAI에서 어제 공개한 새로운 생성형 AI 모델 Sora에 대해서 알아보겠습니다. Sora는 다양한 길이, 종횡비 및 해상도를 가진 비디오 및 이미지를 생성할 수 있는 시각 데이터 모
fornewchallenge.tistory.com
'AI 도구' 카테고리의 다른 글
| 💥핵꿀팁! 스마트폰에서 Ollama WebUI를 만나는 방법 (ngrok 활용) (0) | 2024.02.21 |
|---|---|
| LangChain과 CrewAI를 활용한 News 검색-분석-요약 자동화 (2) | 2024.02.20 |
| 🚀Ollama와 Instructor를 활용한 대규모 언어 모델과의 상호 작용 가이드 (0) | 2024.02.15 |
| AutoGen: 토큰 과금 없는 100% 무료 대규모 언어 모델 협업 자동화 (2) | 2024.02.13 |
| Ollama 업데이트! 이제 OpenAI API를 무료로 즐기세요! (1) | 2024.02.12 |




