목차
안녕하세요! 최근 자연어 처리(NLP)와 정보 검색 분야에서의 진화 속에서 대규모 언어 모델과 효율적인 데이터 저장기술이 만나면서 많은 발전이 이뤄지고 있는데요. 오늘은 대규모 언어 모델 Solar와 Mistral 7B를 이용해서 고객의 리뷰를 분석하고 인사이트를 도출해 보겠습니다. 이 블로그 포스트에서는 대규모 언어 모델의 이용을 편리하게 만들기 위한 Ollama, ChromaDB, Llama Index와 같은 AI도구의 활용방법에 대해 확인하실 수 있습니다. 자, 그럼 출발해 보실까요?

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
프로젝트 개요
이 프로젝트는 고객의 리뷰 1,000개가 저장되어 있는 CSV파일을 업로드한 후, 리뷰분석을 요청하면, Llama Index 라이브러리가 문서 데이터를 벡터로 변환하여 ChromaDB 벡터저장소에 저장하고, 쿼리를 수행하며, Ollama에서 불러온 대규모 언어 모델이 쿼리결과를 분석한 후, 최종 인사이트를 출력하게 됩니다.

다음은 이 블로그에서 사용되는 대규모 언어 모델 활용 도구에 대한 설명입니다.
- Ollama: 대규모 언어 모델을 웹 애플리케이션에서 활용할 수 있도록 도와주는 도구 중 하나입니다. Ollama는 로컬에서 실행되는 대규모 언어모델을 웹 앱에서 사용할 수 있도록 지원하며, 오픈소스 기반으로 로컬 언어모델 실행, 웹 앱과의 통합, 쉘 명령어 인터페이스와 같은 기능을 제공합니다.
- Llama Index: 벡터 인덱싱을 기반으로 한 정보 검색 및 질의 처리를 위한 라이브러리입니다. 벡터 인덱싱은 문서나 데이터를 벡터로 표현하여 유사성을 기반으로 효율적인 검색을 가능케 하는 기술입니다. Llama Index는 이러한 개념을 구현하여 대용량 텍스트 데이터에 대한 빠르고 효과적인 검색을 제공합니다. 이를 위해 문서를 벡터로 변환, 저장, 검색하기 위한 인프라를 제공합니다.
- ChromaDB: 벡터 데이터를 저장하고 효율적으로 관리하기 위한 오픈소스 데이터베이스입니다. - 벡터 데이터를 다차원 공간에 저장하여 유사성 기반 검색 및 분석을 가능케 합니다. 또한, 데이터를 디스크에 유지하면서도 필요한 경우 메모리에서 빠르게 검색할 수 있습니다. ChromaDB는 대규모 벡터 데이터셋에서 효율적으로 작동하며, 검색 및 분석 작업에 특화된 기능을 제공합니다.
- VectorStore Index: 벡터 데이터를 쿼리할 수 있도록 하는 색인 구조로서, 문서 또는 데이터를 벡터로 표현하고, 이를 인덱싱하여 검색 속도를 높입니다. Llama Index는 문서들을 벡터로 변환하고 이를 ChromaDB 벡터 스토어에 저장하며, 저장된 벡터를 효과적으로 검색하기 위해 쿼리 엔진을 구축하여 자연어 질문에 대한 빠르고 정확한 답을 찾을 수 있도록 합니다.
이러한 기술들은 대규모 텍스트 데이터나 벡터 데이터에 대한 효율적인 관리와 검색을 위해 사용되며, 대규모 언어 모델의 자연어 처리와 벡터 인덱싱을 결합하여 높은 수준의 정보 추출과 분석을 가능하게 합니다.
환경설정 및 종속성 설치
이번 프로젝트는 아직 윈도우 운영체제를 정식으로 지원하지 않는 Ollama를 활용하기 때문에 가상환경 생성과 활성화 모두 WSL(Windows Subsystem for Linux) 프롬프트에서 진행하여야 합니다. WSL 프롬프트에서 가상환경 생성은 "python3.11 -m venv myenv", 활성화는 "source myenv/bin/activate" 명령어를 입력하면 됩니다.
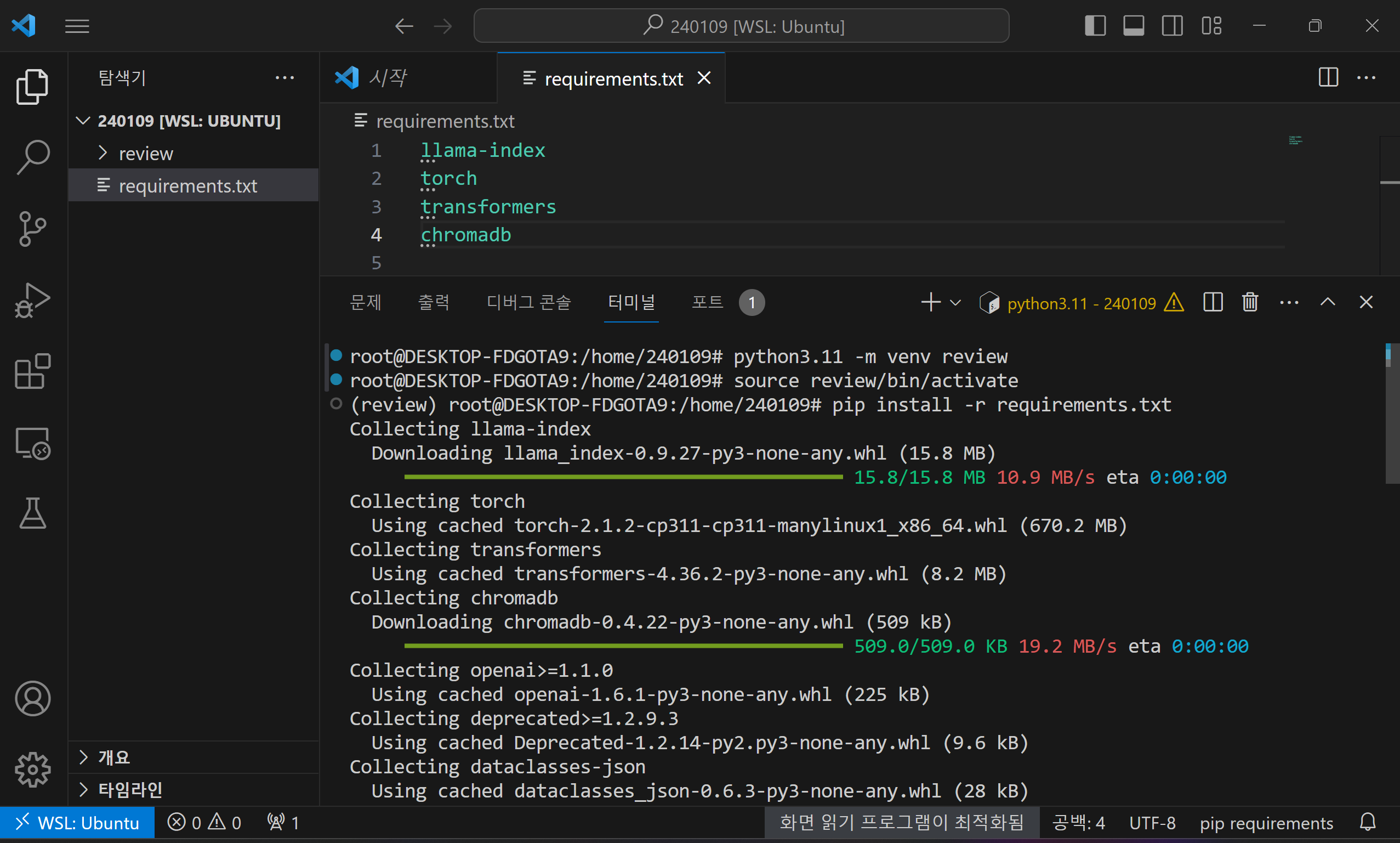
다음은 종속성 설치입니다. 아래에 텍스트 내용을 복사해서 원하는 폴더에 requirements.txt라는 이름으로 파일을 만든 다음 가상환경이 활성화된 WSL 프롬프트에서 "pip install -r requirements.txt" 명령어로 종속성을 설치해 줍니다.
llama-index
torch
transformers
chromadb
gradio
종속성 설치에 포함된 각 라이브러리에 대한 설명은 다음과 같습니다.
- Llama-index: 벡터 인덱싱과 관련된 라이브러리로, 정보 검색 및 질의 처리를 위해 사용됩니다. 자연어 처리 모델과의 통합, 벡터 인덱싱, 쿼리 엔진 등을 포함하여 텍스트 데이터에 대한 효율적인 검색과 분석을 지원합니다.
- Torch: PyTorch라 불리는 오픈소스 머신러닝 라이브러리입니다. 텐서(Tensor) 연산을 위한 다양한 함수와 모듈을 제공하며, 딥 러닝 모델의 구현과 학습을 용이하게 합니다. 주로 신경망을 구현하고 학습시키는 데 사용되며, 동적 계산 그래프를 지원하여 유연하고 직관적인 모델 구현이 가능합니다.
- Transformers: Hugging Face에서 제공하는 라이브러리로, 자연어 처리 모델의 사전 훈련 및 파인 튜닝을 지원합니다. 다양한 사전 훈련된 모델을 포함하고 있어, 자연어 이해 및 생성 작업에 활용됩니다. 텍스트 데이터에 대한 NLP 작업을 간편하게 수행할 수 있도록 모델 구조, 토크나이저, 사전 훈련된 가중치 등을 제공합니다.
- Chromadb: 벡터 데이터를 저장하고 효율적으로 관리하기 위한 데이터베이스입니다. 벡터 데이터를 다차원 공간에 저장하여 유사성 기반 검색 및 분석을 지원합니다. ChromaDB는 대용량 벡터 데이터셋에서 효율적으로 동작하며, 검색과 분석 작업을 위한 기능을 제공합니다.
이러한 라이브러리들은 각자의 목적에 맞게 특화되어 있으며, 텍스트 데이터에 대한 다양한 처리와 분석 작업을 수행할 수 있습니다. 환경설정과 종속성 설치가 완료되면 고객의 리뷰가 저장된 데이터 파일을 CSV 형식으로 준비합니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
파이썬 코드 실행
다음 파이썬 코드 실행단계입니다. 이 코드는 Gradio를 사용하여 대화형 웹 인터페이스를 생성하고, 사용자가 업로드한 CSV 파일에서 특정 질문에 대한 리뷰를 분석하는 작업을 수행합니다. 코드를 실행하기 전에 WSL 프롬프트상에서 "ollama serve"를 입력하여 Ollama를 실행합니다. 다음은 코드의 동작 순서입니다.
- 1. 라이브러리 및 모듈 임포트: 필요한 라이브러리와 모듈을 가져옵니다. Gradio, shutil, Ollama, ChromaDB, VectorStoreIndex 등이 여기에 해당합니다. shutil은 Python 표준 라이브러리에 포함된 모듈로, "shell utility"에서 유래되었으며, 파일 복사, 이동, 삭제, 디렉터리 생성 등 파일 시스템 작업을 수행할 수 있도록 도구를 제공합니다.
- 2. CSV 파일 업로드 및 ChromaDB 초기화: 사용자가 업로드한 CSV 파일을 Gradio 인터페이스의 입력으로 받습니다. `chroma_db_data` 폴더가 이미 존재하면 해당 폴더를 삭제합니다. 이는 새로운 데이터에 대해 ChromaDB를 초기화하기 위한 것입니다.
- 3. CSV 데이터 로딩 및 ChromaDB 설정: 'llama_index' 패키지에서 제공하는 함수`SimpleCSVReader`를 사용하여 업로드한 CSV 파일을 로드합니다. ChromaDB 클라이언트와 컬렉션을 생성하고, ChromaVectorStore와 벡터 저장소 지정을 위한 StorageContext를 설정합니다.
- 4. Ollama 및 ServiceContext 초기화: Ollama 모델을 'Mistral 7B'로 초기화하고, ServiceContext를 설정합니다. 컴퓨터 사양이 낮은 경우 request_timeout을 추가하지 않으면 httpx.Readtimeout이 발생합니다.(매우 중요)
- 5. VectorStoreIndex 및 Query Engine 생성: Documents(로드한 CSV 데이터)를 사용하여 VectorStoreIndex를 생성합니다. 이 인덱스는 문서를 벡터로 변환하고, ChromaDB에 저장한 후, 쿼리 엔진을 초기화합니다.
- 6. Gradio 인터페이스 설정: Gradio를 사용하여 함수 `perform_query`를 이용하는 인터페이스를 설정합니다. 사용자에게 텍스트 입력과 CSV 파일 업로드를 받아들이고, 그 결과로 텍스트 출력을 설정합니다. 인터페이스에는 "대규모 언어 모델을 활용한 고객 리뷰 분석"이라는 제목과 설명이 포함되어 있습니다.
- 7. 인터페이스 실행: `iface.launch()`를 호출하여 Gradio 인터페이스를 실행합니다. 이제 웹 브라우저에서 해당 인터페이스를 확인하고 사용자가 질문과 CSV 파일을 업로드하여 리뷰를 분석할 수 있습니다.
이 동작 순서를 통해 코드는 식품 리뷰 데이터를 자연어 처리 모델을 사용하여 벡터로 표현하고, 이를 ChromaDB에 저장한 후, VectorStoreIndex를 생성하여 쿼리를 수행하며, 고객리뷰에 대한 분석 정보를 추출합니다.
import gradio as gr
import shutil
from llama_index.llms import Ollama
from pathlib import Path
import chromadb
from llama_index import VectorStoreIndex, ServiceContext, download_loader
from llama_index.storage.storage_context import StorageContext
from llama_index.vector_stores.chroma import ChromaVectorStore
# Create a function to perform the query
def perform_query(query, csv_file):
# Check if chroma_db_data folder exists and delete it if it does
chroma_db_path = Path("./chroma_db_data")
if chroma_db_path.exists():
shutil.rmtree(chroma_db_path)
# Load CSV data
SimpleCSVReader = download_loader("SimpleCSVReader")
loader = SimpleCSVReader(encoding="utf-8")
documents = loader.load_data(file=csv_file)
# Create Chroma DB client and store
client = chromadb.PersistentClient(path="./chroma_db_data")
chroma_collection = client.create_collection(name="reviews")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# Initialize Ollama and ServiceContext
llm = Ollama(model="mistral", request_timeout=3600)
service_context = ServiceContext.from_defaults(llm=llm, embed_model="local")
# Create VectorStoreIndex and query engine
index = VectorStoreIndex.from_documents(documents, service_context=service_context, storage_context=storage_context)
query_engine = index.as_query_engine()
# Perform the query and return the response
response = query_engine.query(query)
return response
# Create the Gradio interface
iface = gr.Interface(fn=perform_query, inputs=["text", gr.components.File(label="Upload CSV")], outputs="text",
title="대규모 언어 모델을 활용한 고객 리뷰 분석", description="고객리뷰 CSV파일과 질문을 입력하고 인사이트를 얻으세요",
examples=[["What are the thoughts on food quality?"]])
# Run the interface
iface.launch()
위 코드 중에서 llm = Ollama(model="mistral", request_timeout=3600)에 나오는 모델명은 Ollama에서 지원하는 대규모 언어 모델로 변경하여 지정이 가능합니다. 다음은 Mistral 7B와 Solar 10.7B의 분석결과 화면입니다.
코드를 실행하고 http://127.0.0.1:7860/의 주소로 웹 브라우저에 접속하면 다음과 같은 초기화면이 열립니다. CSV파일을 업로드하고, QUERY 칸에 분석요청내용을 입력하면 OUTPUT 칸에 분석결과가 표시됩니다. 컴퓨터의 성능에 따라 처리시간은 모델의 크기가 10B 이상인 경우 수 분이상 소요될 수 있습니다.
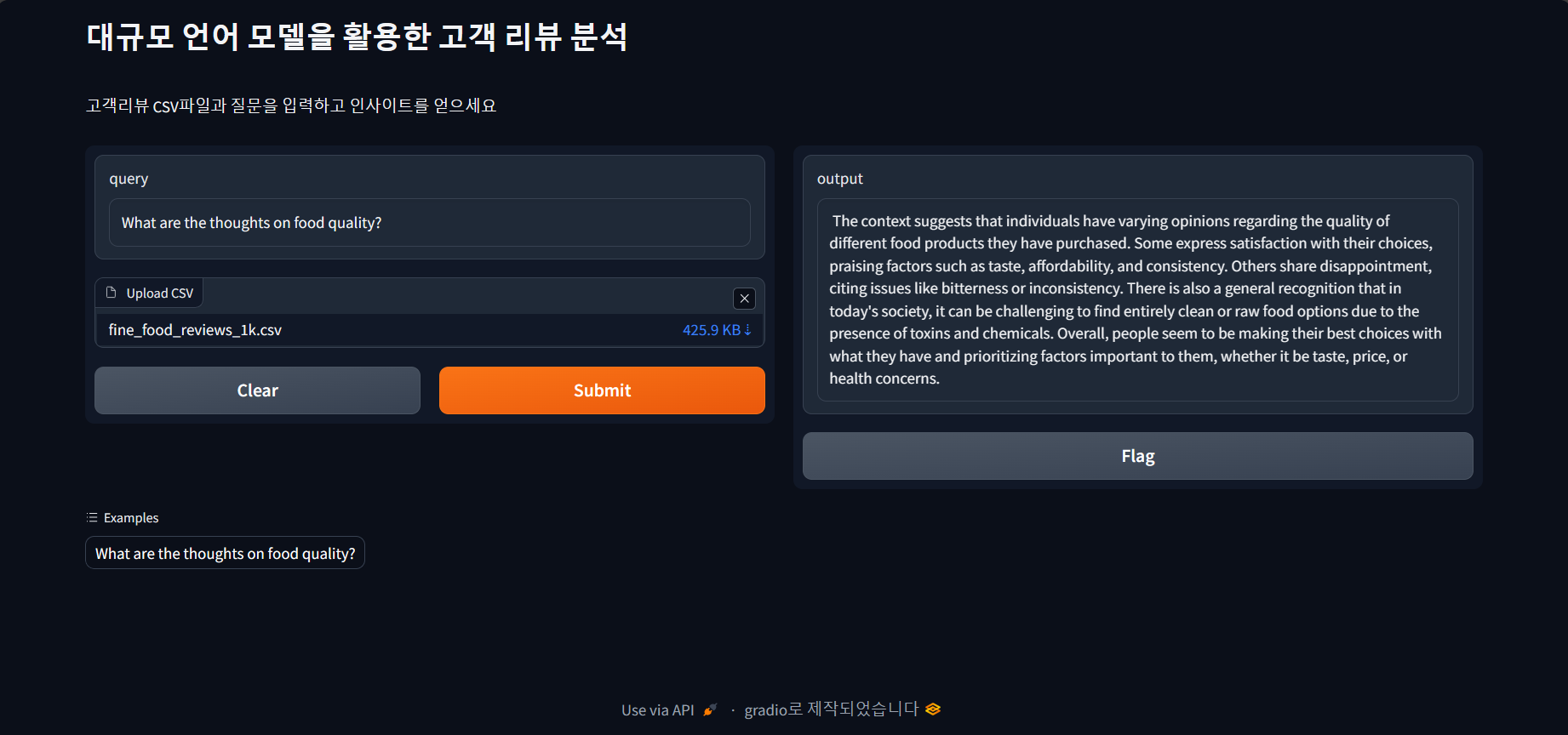
다음은 Mistral 7B의 고객 리뷰 분석 결과입니다. 리뷰 분석 결과에 따라 상세내용을 추가로 질의할 수도 있습니다. 추가 질의를 할 경우에는 콜렉션 중복 에러가 발생하므로, 브라우저 및 스크립트 종료 후 다시 실행하시거나, 벡터스토어 콜렉션의 자동삭제기능을 추가하시면 좋을 것 같습니다.
리뷰는 개인이 구매한 다양한 식품의 품질에 대해 다양한 의견을 가지고 있음을 시사합니다.
일부는 맛, 가격 및 일관성과 같은 요소를 칭찬하며 선택에 만족을 표현합니다. 다른 사람들은 쓴맛 또는 일관성과
같은 문제를 언급하며 실망감을 공유합니다.
또한 오늘날의 사회에서는 독소 및 화학 물질의 존재로 인해 완전히 깨끗한 또는 날 것의 식품을 선택하는 것이
어려울 수 있다는 일반적인 인식이 있습니다.
전반적으로 사람들은 맛, 가격 또는 건강 문제와 상관없이 자신에게 중요한 요소를 우선시하고 가지고 있는 것으로
최선의 선택을 하는 것으로 보입니다.
다음은 쓴맛 또는 음식의 일관성과 관련된 부정적인 리뷰에 대한 상세 분석 요청결과입니다.
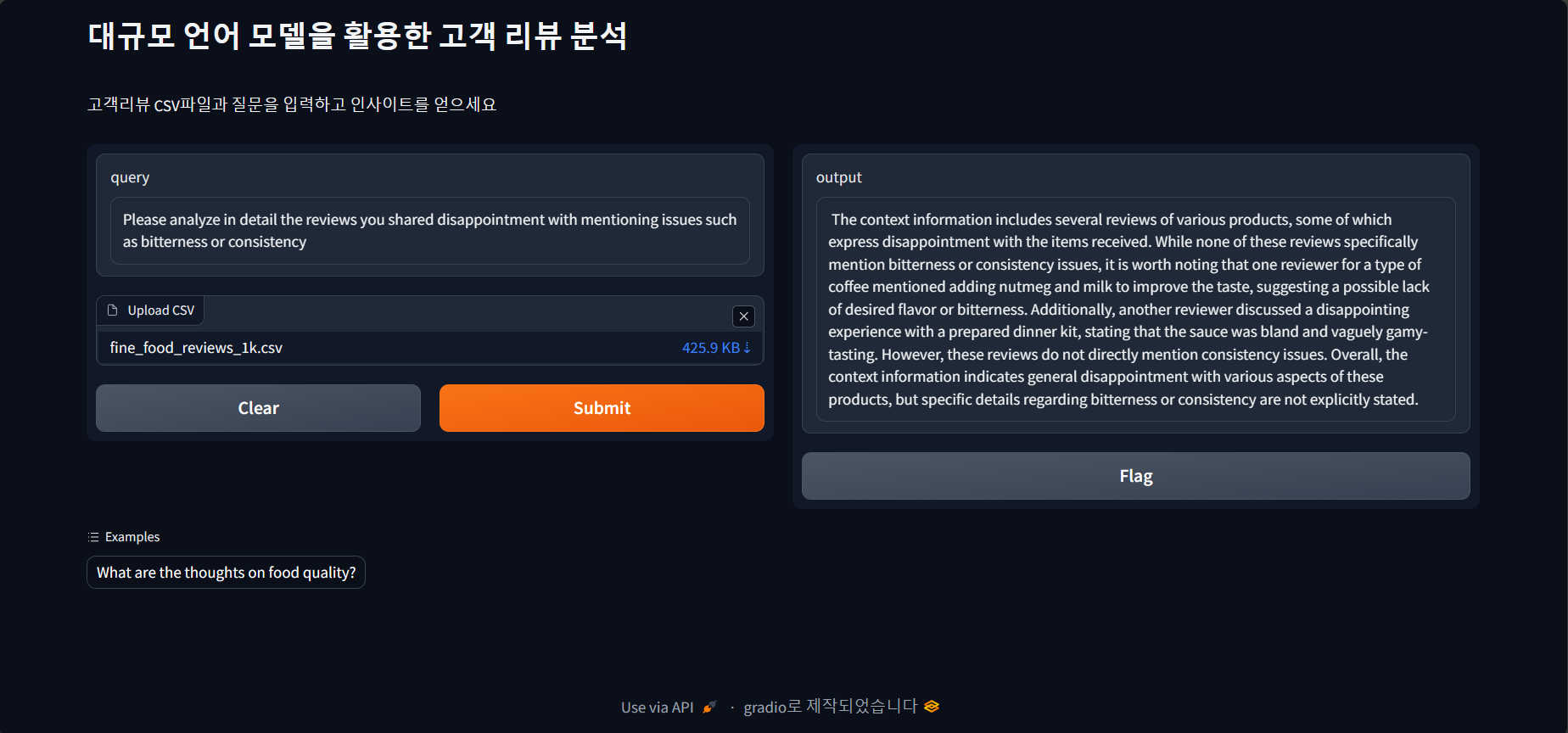
상황 정보에는 다양한 제품에 대한 여러 리뷰가 포함되어 있으며, 그 중 일부는 받은 제품에 대해 실망감을
표시합니다. 이러한 리뷰 중 어느 것도 쓴맛이나 일관성 문제를 구체적으로 언급하지 않았지만, 커피 유형에
대한 한 리뷰어가 맛을 개선하기 위해 육두구와 우유를 추가하는 것을 언급하여 원하는 맛이나 쓴맛이 부족할
수 있음을 시사한다는 점에 주목할 필요가 있습니다. 또한 다른 리뷰어는 준비된 디너 키트에서 소스가 싱겁고
모호하게 감칠맛이 난다고 말하며 실망스러운 경험을 논의했습니다. 그러나 이러한 리뷰는 일관성 문제를
직접적으로 언급하지는 않습니다. 전반적으로 상황 정보는 이러한 제품의 다양한 측면에 대한 일반적인 실망감을
나타내지만 쓴맛이나 일관성에 대한 구체적인 세부 사항은 명시적으로 언급되지 않았습니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
마치며
이번 프로젝트를 통해 대규모 언어 모델과 효율적인 데이터 저장 기술의 결합이 어떻게 혁신적인 리뷰 분석 도구를 만들어내는지 살펴보았습니다. Ollama, ChromaDB, Llama Index는 각각 언어 모델 실행, 벡터 데이터 저장, 벡터 인덱싱을 담당하며, 이들을 통합하여 고객 리뷰에 대한 효율적이고 정확한 분석을 제공할 수 있습니다.
Ollama의 Mistral 7B와 Solar 10.7B를 비롯한 다양한 언어 모델 실행이 가능하며, Llama Index와 ChromaDB를 활용하여 텍스트 데이터를 벡터로 표현하고 효율적으로 저장, 검색할 수 있습니다. 이를 통해 사용자는 자연어 질문을 통해 고객 리뷰 데이터에 빠르게 접근하고 심층적인 분석을 수행할 수 있습니다.
또한, Gradio를 활용한 대화형 웹 인터페이스를 통해 사용자가 쉽게 리뷰를 분석하고 결과를 확인할 수 있으며, 이러한 사용자 친화적인 인터페이스는 비전문가도 쉽게 활용 가능하여, 실제 고객 리뷰에 대한 통찰력을 얻을 수 있도록 도와줍니다. 향후에는 대규모 언어 모델과 데이터 저장 기술의 결합이 좀더 다양한 응용 분야에서의 혁신을 이끌어낼 것으로 기대됩니다. 저는 그럼 다음에 더 유익한 정보를 가지고 다시 찾아뵙겠습니다. 감사합니다.
2024.01.07 - [대규모 언어모델] - CrewAI를 이용한 대규모 언어 모델 Solar와 Hermes의 협업 프로젝트
CrewAI를 이용한 대규모 언어 모델 Solar와 Hermes의 협업 프로젝트
안녕하세요! 오늘은 CrewAI라는 도구를 이용해서 국산 대규모 언어 모델 Solar와 Mistral 7B의 미세조정 모델인 Hermes의 협업 프로젝트를 만들어 보겠습니다. CrewAI는 인공 지능(AI) 에이전트에게 역할을
fornewchallenge.tistory.com
'AI 도구' 카테고리의 다른 글
| Ollama Python 라이브러리와 RAG으로 웹 사이트 요약하기 (4) | 2024.01.28 |
|---|---|
| Open Interpreter: 내PC 브라우저 제어, 파일 변환, PDF 요약까지 (2) | 2024.01.27 |
| 텍스트 임베딩을 이용한 벡터검색 Q&A 시스템 만들기 (4) | 2024.01.07 |
| 고성능 그래픽카드 없이도 실시간 이미지 생성 가능! KREA AI (0) | 2023.12.11 |
| Fooocus: 이미지 생성의 새로운 차원을 여는 AI 아트 소프트웨어! (0) | 2023.12.09 |




